Due to a bug, there are many duplicate folders in a file system. You are given a 2D array paths, where paths[i] is an array representing an absolute path to the ith folder in the file system.
["one", "two", "three"] represents the path "/one/two/three".Two folders (not necessarily on the same level) are identical if they contain the same non-empty set of identical subfolders and underlying subfolder structure. The folders do not need to be at the root level to be identical. If two or more folders are identical, then mark the folders as well as all their subfolders.
"/a" and "/b" in the file structure below are identical. They (as well as their subfolders) should all be marked:
/a/a/x/a/x/y/a/z/b/b/x/b/x/y/b/z"/b/w", then the folders "/a" and "/b" would not be identical. Note that "/a/x" and "/b/x" would still be considered identical even with the added folder.Once all the identical folders and their subfolders have been marked, the file system will delete all of them. The file system only runs the deletion once, so any folders that become identical after the initial deletion are not deleted.
Return the 2D array ans containing the paths of the remaining folders after deleting all the marked folders. The paths may be returned in any order.
Example 1:
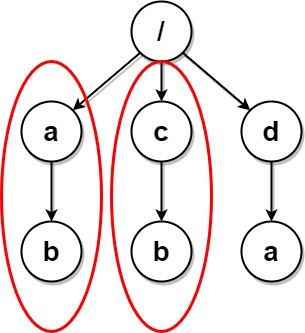
Input: paths = [["a"],["c"],["d"],["a","b"],["c","b"],["d","a"]] Output: [["d"],["d","a"]] Explanation: The file structure is as shown. Folders "/a" and "/c" (and their subfolders) are marked for deletion because they both contain an empty folder named "b".
Example 2:
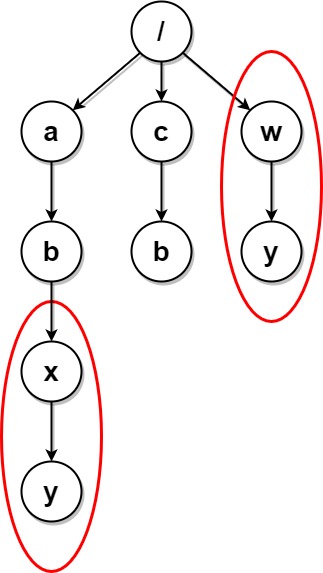
Input: paths = [["a"],["c"],["a","b"],["c","b"],["a","b","x"],["a","b","x","y"],["w"],["w","y"]] Output: [["c"],["c","b"],["a"],["a","b"]] Explanation: The file structure is as shown. Folders "/a/b/x" and "/w" (and their subfolders) are marked for deletion because they both contain an empty folder named "y". Note that folders "/a" and "/c" are identical after the deletion, but they are not deleted because they were not marked beforehand.
Example 3:
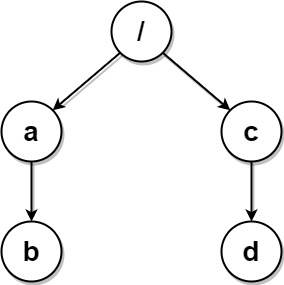
Input: paths = [["a","b"],["c","d"],["c"],["a"]] Output: [["c"],["c","d"],["a"],["a","b"]] Explanation: All folders are unique in the file system. Note that the returned array can be in a different order as the order does not matter.
Constraints:
1 <= paths.length <= 2 * 1041 <= paths[i].length <= 5001 <= paths[i][j].length <= 101 <= sum(paths[i][j].length) <= 2 * 105path[i][j] consists of lowercase English letters.Problem Overview: You receive a list of folder paths that represent a virtual file system. If two folders contain identical subfolder structures, both folders (and their subtrees) must be removed. The task is to detect structurally identical folder trees and return the remaining folder paths.
Approach 1: Tree Serialization with Hashing (O(n * k) time, O(n * k) space)
Build a directory tree using a trie-like structure where each node represents a folder. Each path from the input list is inserted into the tree. After constructing the tree, perform a post-order traversal to serialize every subtree. The serialization string encodes the folder name and the ordered representation of its children. Store each serialization in a hash table to count occurrences. If the same serialized structure appears more than once, mark those nodes as duplicates. A second traversal collects only the folders that are not part of duplicate subtrees.
The key insight: two folders are duplicates if their entire subtree structure is identical. Serialization converts tree structure comparison into simple hash comparisons. Post-order traversal ensures child structures are processed before their parent folders.
Approach 2: Hashing Subfolder Structures (O(n * k) time, O(n * k) space)
This variation also constructs the folder tree but focuses on computing structural hashes instead of long serialization strings. Each node generates a hash based on its folder name and the hashes of its children. Child hashes are sorted and combined to create a canonical representation of the subtree. The resulting hash is stored in a frequency map. If multiple nodes produce the same hash, those folders represent duplicate subtrees.
Using hashes instead of long serialized strings reduces memory overhead and speeds up comparisons. The algorithm still relies on a bottom-up traversal so that every folder's structure is uniquely determined by its children.
Both approaches depend on representing folder hierarchies as a tree and comparing subtree structures using hashing. The use of string serialization or structural hashes converts a complex tree comparison problem into efficient map lookups.
Recommended for interviews: Tree serialization with hashing is the approach most interviewers expect. It clearly demonstrates how to model hierarchical data using a trie and how to detect duplicate structures with hashing. Explaining the serialization idea first shows strong problem decomposition, while the hash-based optimization shows awareness of performance tradeoffs.
This approach involves building a tree to represent the file system structure. Serialize each subtree and use a hashmap to count occurrences of each serialized subtree. Duplicates are identified by those serializations that occur more than once and marked for deletion.
The solution constructs a tree representation of the file system using a nested dictionary structure. It then serializes each subtree into a string representation and records them in a hashmap, subtree_map, which maps serialized strings to subtrees.
Any subtree occurring more than once is marked for deletion. The filtering step constructs a new tree excluding these marked subtrees, and the extract_paths function then rebuilds all paths from the remaining tree structure.
Time Complexity: O(n * m * log(m)), where n is the number of paths and m is the average number of nodes in a path, due to sorting of folders for serialization.
Space Complexity: O(n * m) for storing the tree and serializations.
This approach relies on hashing to uniquely identify subfolder structures. By hashing the contents of each folder, including its subfolders recursively, we can identify folders with identical structures. A map is used to store these hashes, and any hash with a count greater than one indicates duplicate subfolder structures.
This C++ implementation uses a custom TreeNode structure to represent folders and uses maps for managing child nodes. Each TreeNode also has a deleted boolean to indicate whether it is marked for deletion.
After tree construction, each TreeNode is serialized through hashing, with results stored in an unordered map. Subtrees with identical hashes are marked via the map, and paths are then collected from non-deleted nodes.
C++
JavaScript
Time Complexity: O(n * m * log(m)), where n is the number of folder paths and m is the average number of nodes (folders) in a path, due to sorting operations for serialization.
Space Complexity: O(n * m) required for tree and hashmap storage.
We can use a trie to store the folder structure, where each node in the trie contains the following data:
children: A dictionary where the key is the name of the subfolder and the value is the corresponding child node.deleted: A boolean value indicating whether the node is marked for deletion.We insert all paths into the trie, then use DFS to traverse the trie and build a string representation for each subtree. For each subtree, if its string representation already exists in a global dictionary, we mark both the current node and the corresponding node in the global dictionary for deletion. Finally, we use DFS again to traverse the trie and add the paths of unmarked nodes to the result list.
Python
Java
C++
Go
TypeScript
| Approach | Complexity |
|---|---|
| Tree Serialization with Hashing | Time Complexity: O(n * m * log(m)), where n is the number of paths and m is the average number of nodes in a path, due to sorting of folders for serialization. Space Complexity: O(n * m) for storing the tree and serializations. |
| Hashing Subfolder Structures | Time Complexity: O(n * m * log(m)), where n is the number of folder paths and m is the average number of nodes (folders) in a path, due to sorting operations for serialization. Space Complexity: O(n * m) required for tree and hashmap storage. |
| Trie + DFS | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Tree Serialization with Hashing | O(n * k) | O(n * k) | Standard interview solution. Easy to reason about subtree equality using serialized strings. |
| Hashing Subfolder Structures | O(n * k) | O(n * k) | When large serialized strings become expensive and structural hashing improves performance. |
| Naive Subtree Comparison | O(n^2 * k) | O(n * k) | Conceptual baseline for understanding duplicate subtree detection but not practical for large inputs. |
Delete Duplicate Folders in System | Super Detailed Explanation | Leetcode 1948 | codestorywithMIK • codestorywithMIK • 8,769 views views
Watch 9 more video solutions →Practice Delete Duplicate Folders in System with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor