An n x n matrix is valid if every row and every column contains all the integers from 1 to n (inclusive).
Given an n x n integer matrix matrix, return true if the matrix is valid. Otherwise, return false.
Example 1:
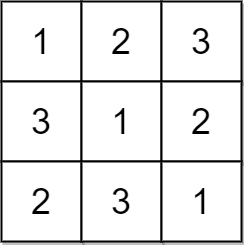
Input: matrix = [[1,2,3],[3,1,2],[2,3,1]] Output: true Explanation: In this case, n = 3, and every row and column contains the numbers 1, 2, and 3. Hence, we return true.
Example 2:
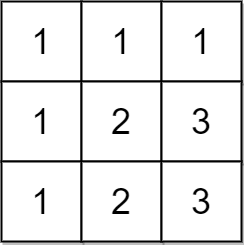
Input: matrix = [[1,1,1],[1,2,3],[1,2,3]] Output: false Explanation: In this case, n = 3, but the first row and the first column do not contain the numbers 2 or 3. Hence, we return false.
Constraints:
n == matrix.length == matrix[i].length1 <= n <= 1001 <= matrix[i][j] <= nProblem Overview: You are given an n x n matrix where values should range from 1 to n. The task is to verify that every row and every column contains all numbers from 1..n exactly once. If any row or column is missing a value or contains duplicates, the matrix is invalid.
Approach 1: Use Sets for Validation (Time: O(n2), Space: O(n))
This method uses a set to ensure uniqueness in each row and column. Iterate through the matrix row by row. For each row, insert elements into a set and verify that the set size becomes n while ensuring every value lies in the range 1..n. Repeat the same validation for every column. If any insertion encounters duplicates or invalid numbers, the matrix fails immediately. Set lookups and insertions are constant time on average, making the overall traversal O(n²).
This approach is intuitive and easy to implement. It relies on hash-based uniqueness checks, a common pattern when working with hash tables. Since each row and column requires its own temporary set, space usage stays at O(n). Most developers reach for this solution first because it is concise and hard to get wrong.
Approach 2: Use Count Arrays for Validation (Time: O(n2), Space: O(n))
Instead of hash sets, use a frequency array of size n + 1 for rows and columns. While iterating through a row, increment the count for matrix[i][j]. If the value is outside 1..n or its count exceeds 1, the row is invalid. Reset the array and repeat the process for each column. This approach replaces hashing with direct index access, which can be slightly faster and more memory predictable.
This pattern appears frequently in array and matrix validation problems where values fall within a known range. Since the value range is bounded by n, a counting structure becomes a natural fit.
Recommended for interviews: Both solutions run in O(n²) time, which is optimal because every cell must be inspected at least once. The set-based approach is typically preferred in interviews due to readability and fewer edge cases. The count-array version demonstrates deeper understanding of frequency tracking and constant-time indexing. Showing both approaches communicates strong problem-solving depth.
This approach leverages the property of sets to store unique elements. The idea is to use a set to check each row and column. For each row and column, we transform the elements into a set and compare it with a reference set containing all numbers from 1 to n. If both sets are equal for every row and column, the matrix is valid.
The C solution defines two arrays, one for the current row and one for the current column, resetting them for every row iteration. It uses these arrays to count the occurrences of each number, ensuring all numbers from 1 to n appear exactly once in each row and each column.
Time Complexity: O(n^2), where n is the size of the matrix, since we iterate over each element of the matrix once.
Space Complexity: O(n), for the auxiliary space used in the row and column arrays.
This approach uses counting arrays to verify the numbers 1 to n in each row and column. We maintain a count of occurrences for each number in an row-count and column-count array. Post-increment in the matrix traversal, we check if every number from 1 to n appears exactly once.
In this C solution, we use rowCount and colCount arrays to track the number of times each integer appears. This ensures every integer appears exactly once per row and column, leading to a correct validation.
Time Complexity: O(n^2), iterating through the matrix twice.
Space Complexity: O(n^2), maintaining count arrays for rows and columns.
Traverse each row and column of the matrix, using a hash table to record whether each number has appeared. If any number appears more than once in a row or column, return false; otherwise, return true
The time complexity is O(n^2), and the space complexity is O(n). Here, n is the size of the matrix.
Python
Java
C++
Go
TypeScript
| Approach | Complexity |
|---|---|
| Approach 1: Use Sets for Validation | Time Complexity: O(n^2), where n is the size of the matrix, since we iterate over each element of the matrix once. |
| Approach 2: Use Count Arrays for Validation | Time Complexity: O(n^2), iterating through the matrix twice. |
| Hash Table | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Use Sets for Validation | O(n²) | O(n) | Best general solution. Simple to implement with hash-based duplicate detection. |
| Use Count Arrays for Validation | O(n²) | O(n) | When values are guaranteed within 1..n and you want faster constant-time indexing without hashing. |
Check if Every Row and Column Contains All Numbers | Leetcode 2133 | Contest 275 | 2 Approaches 🔥🔥🔥 • Coding Decoded • 2,416 views views
Watch 9 more video solutions →Practice Check if Every Row and Column Contains All Numbers with our built-in code editor and test cases.
Practice on FleetCode