Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment.
Design an algorithm to serialize and deserialize a binary tree. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that a binary tree can be serialized to a string and this string can be deserialized to the original tree structure.
Clarification: The input/output format is the same as how LeetCode serializes a binary tree. You do not necessarily need to follow this format, so please be creative and come up with different approaches yourself.
Example 1:
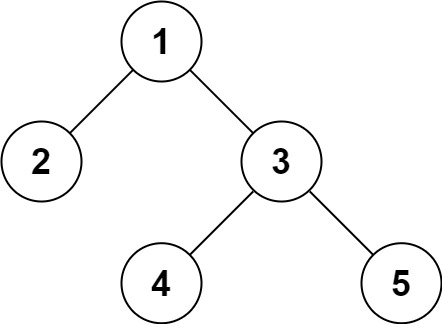
Input: root = [1,2,3,null,null,4,5] Output: [1,2,3,null,null,4,5]
Example 2:
Input: root = [] Output: []
Constraints:
[0, 104].-1000 <= Node.val <= 1000The goal of Serialize and Deserialize Binary Tree is to convert a binary tree into a string representation and reconstruct the exact same tree later. A common strategy is to traverse the tree and record node values along with markers for null children so that the structure can be preserved.
One popular method uses Depth-First Search (DFS) with preorder traversal. During serialization, each node value is appended to the string, while missing children are represented with a special symbol such as #. During deserialization, the sequence is read in order and the tree is rebuilt recursively by reconstructing left and right subtrees.
Another approach uses Breadth-First Search (BFS) with a queue, storing nodes level by level and inserting placeholders for null nodes. Both approaches ensure the structure and values of the tree are preserved. Since every node is processed once, the algorithm runs in O(n) time with O(n) space for storing the serialized data and recursion or queue structures.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| DFS Preorder Serialization | O(n) | O(n) |
| BFS Level Order Serialization | O(n) | O(n) |
take U forward
This approach involves using a HashMap (or dictionary in Python) to count the occurrences of each element in the array. This will help in efficiently checking if an element exists and how many times it appears, which is useful for problems requiring frequency analysis.
Time Complexity: O(n), as it iterates over the array once. Space Complexity: O(1) if the element range is known and constant, or O(k) where k is the range of elements.
1using System;
2using System.Collections.Generic;
3
4class ElementCounter {
5 static void CountElements(int[] arr) {
6 Dictionary<int, int> frequency = new Dictionary<int, int>();
7 foreach (int num in arr) {
8 if (frequency.ContainsKey(num)) {
9 frequency[num]++;
10 } else {
11 frequency[num] = 1;
12 }
13 }
14 foreach (var kvp in frequency) {
Console.WriteLine($"Element {kvp.Key} appears {kvp.Value} times");
}
}
static void Main() {
int[] arr = {1, 3, 1, 2, 3, 4, 5, 3};
CountElements(arr);
}
}The C# solution uses the Dictionary class to count frequencies of elements. This approach benefits from C#'s efficient implementation of hash tables for rapid insertion and lookup.
Another approach is sorting the array and then identifying repeated elements by comparison with neighboring elements. This leverages the efficiency of modern sorting algorithms to bring repeated elements together, making it trivial to count consecutive duplicates.
Time Complexity: O(n log n) due to the sort operation. Space Complexity: O(1) if in-place sorting is considered.
1#include <algorithm>
using namespace std;
void countSortedElements(int arr[], int size) {
sort(arr, arr + size);
int count = 1;
for (int i = 1; i < size; i++) {
if (arr[i] == arr[i - 1]) {
count++;
} else {
cout << "Element " << arr[i - 1] << " appears " << count << " times\n";
count = 1;
}
}
cout << "Element " << arr[size - 1] << " appears " << count << " times\n";
}
int main() {
int arr[] = {1, 3, 1, 2, 3, 4, 5, 3};
int size = sizeof(arr) / sizeof(arr[0]);
countSortedElements(arr, size);
return 0;
}Watch expert explanations and walkthroughs
Practice problems asked by these companies to ace your technical interviews.
Explore More ProblemsJot down your thoughts, approach, and key learnings
Null markers ensure that the exact structure of the binary tree is preserved during serialization. Without them, it would be impossible to distinguish between different tree shapes that produce the same traversal sequence. They allow the deserialization process to rebuild missing left and right children correctly.
Yes, this problem is commonly asked in FAANG and other top tech company interviews. It tests understanding of tree traversal, recursion, and system design concepts related to data encoding and reconstruction. Mastering both DFS and BFS approaches is useful for interview preparation.
Common data structures include recursion stacks for DFS or queues for BFS traversal. DFS relies on recursive calls to rebuild the tree structure, while BFS uses a queue to process nodes level by level. Both approaches effectively maintain the structure of the tree.
The optimal approach typically uses DFS preorder traversal with null markers. By storing node values and placeholders for missing children, the exact tree structure can be reconstructed during deserialization. This method processes each node once, resulting in O(n) time complexity.
C++ provides a convenient sort function via the algorithm header, making it easy to arrange elements and subsequently count them by comparison of neighbors.