You are given a tree (i.e. a connected, undirected graph that has no cycles) consisting of n nodes numbered from 0 to n - 1 and exactly n - 1 edges. The root of the tree is the node 0, and each node of the tree has a label which is a lower-case character given in the string labels (i.e. The node with the number i has the label labels[i]).
The edges array is given on the form edges[i] = [ai, bi], which means there is an edge between nodes ai and bi in the tree.
Return an array of size n where ans[i] is the number of nodes in the subtree of the ith node which have the same label as node i.
A subtree of a tree T is the tree consisting of a node in T and all of its descendant nodes.
Example 1:
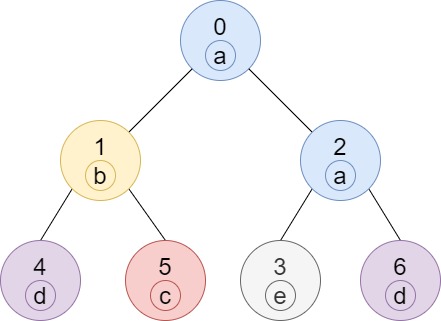
Input: n = 7, edges = [[0,1],[0,2],[1,4],[1,5],[2,3],[2,6]], labels = "abaedcd" Output: [2,1,1,1,1,1,1] Explanation: Node 0 has label 'a' and its sub-tree has node 2 with label 'a' as well, thus the answer is 2. Notice that any node is part of its sub-tree. Node 1 has a label 'b'. The sub-tree of node 1 contains nodes 1,4 and 5, as nodes 4 and 5 have different labels than node 1, the answer is just 1 (the node itself).
Example 2:
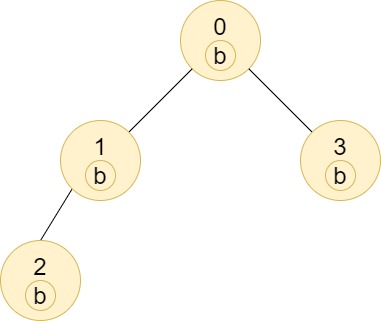
Input: n = 4, edges = [[0,1],[1,2],[0,3]], labels = "bbbb" Output: [4,2,1,1] Explanation: The sub-tree of node 2 contains only node 2, so the answer is 1. The sub-tree of node 3 contains only node 3, so the answer is 1. The sub-tree of node 1 contains nodes 1 and 2, both have label 'b', thus the answer is 2. The sub-tree of node 0 contains nodes 0, 1, 2 and 3, all with label 'b', thus the answer is 4.
Example 3:
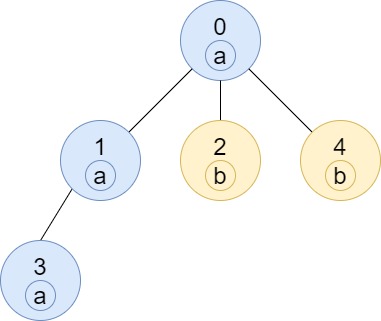
Input: n = 5, edges = [[0,1],[0,2],[1,3],[0,4]], labels = "aabab" Output: [3,2,1,1,1]
Constraints:
1 <= n <= 105edges.length == n - 1edges[i].length == 20 <= ai, bi < nai != bilabels.length == nlabels is consisting of only of lowercase English letters.The key idea for solving #1519 Number of Nodes in the Sub-Tree With the Same Label is to traverse the tree and count how many nodes in each subtree share the same label as the root of that subtree. Since the structure is a tree, we can efficiently explore it using Depth-First Search (DFS).
First, convert the edge list into an adjacency list so each node knows its neighbors. Then run a DFS starting from node 0. For every node, maintain a frequency count of labels in its subtree. Each recursive call returns a count array (or map) representing how many times each label appears in that subtree.
When visiting a node, combine the counts from its children and update the count for the node’s own label. The value corresponding to that label becomes the answer for that node. This bottom-up aggregation ensures every subtree is processed once.
Because each node and edge is visited only once, the algorithm runs in O(n) time with O(n) space for recursion and label counts.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| Depth-First Search with label frequency counting | O(n) | O(n) |
Programming Live with Larry
Use these hints if you're stuck. Try solving on your own first.
Start traversing the tree and each node should return a vector to its parent node.
The vector should be of length 26 and have the count of all the labels in the sub-tree of this node.
This approach utilizes a Depth First Search (DFS) to traverse each node of the tree. During traversal, we maintain a frequency array for each node to keep count of each label in its subtree. The recursion allows merging results from child nodes to calculate the current node's results.
The time complexity is O(n), where n is the number of nodes, because each node and edge is visited once during the DFS traversal. The space complexity is O(n), required for storing the graph representation and frequency arrays.
1import java.util.ArrayList;
2import java.util.List;
3
4class Solution {
5
The Java solution creates a graph using adjacency lists. A depth-first traversal is performed, where a frequency array at each node counts occurrences of each label in the subtree. After recursively merging results from child nodes to the parent, the result for each node is determined by how many times its label appears.
This alternative approach utilizes a HashMap to dynamically manage counts of node labels as opposed to fixed-size arrays. The hash map structure allows potential extension to accommodate varying character sets, though for this problem, it's implemented for the fixed set of labels 'a' to 'z'.
The solution has a time complexity of O(n) given tree node analysis occurs once each during DFS with label counting operations. Space complexity is O(n), due to memory allocations for the graph and storage structures.
Watch expert explanations and walkthroughs
Practice problems asked by these companies to ace your technical interviews.
Explore More ProblemsJot down your thoughts, approach, and key learnings
While BFS can traverse the tree, it is less convenient for aggregating subtree information because subtree results must be processed bottom-up. DFS is typically preferred since recursion naturally processes children before combining their results.
Yes, this type of tree traversal and counting problem is common in FAANG-style interviews. It tests understanding of DFS, tree representation using adjacency lists, and aggregation of results from recursive calls.
An adjacency list is ideal for representing the tree because it allows efficient traversal of neighbors. Additionally, an array or hash map can be used to track label frequencies while combining results from child subtrees during DFS.
The optimal approach uses Depth-First Search (DFS) on the tree while maintaining frequency counts of labels in each subtree. Each node aggregates label counts returned from its children and determines how many nodes share its label within the subtree. This ensures linear time processing.
JavaScript's Map provides flexible node count management in this implementation. Employing DFS, the technique dynamically adjusts label frequencies, efficiently merging child findings upward to compute each node's result for its subtree, well accommodated by the map structure.