You are given the root of a binary tree and an integer distance. A pair of two different leaf nodes of a binary tree is said to be good if the length of the shortest path between them is less than or equal to distance.
Return the number of good leaf node pairs in the tree.
Example 1:
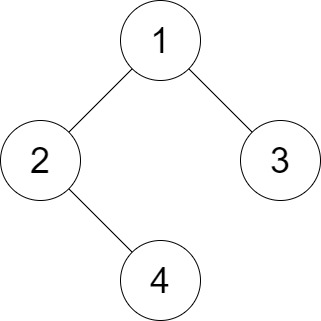
Input: root = [1,2,3,null,4], distance = 3 Output: 1 Explanation: The leaf nodes of the tree are 3 and 4 and the length of the shortest path between them is 3. This is the only good pair.
Example 2:
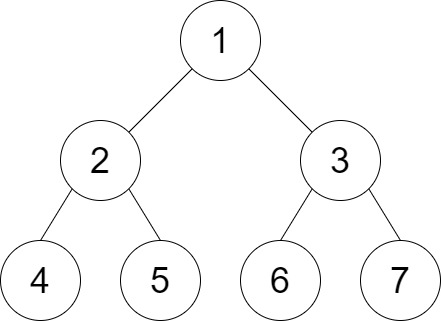
Input: root = [1,2,3,4,5,6,7], distance = 3 Output: 2 Explanation: The good pairs are [4,5] and [6,7] with shortest path = 2. The pair [4,6] is not good because the length of ther shortest path between them is 4.
Example 3:
Input: root = [7,1,4,6,null,5,3,null,null,null,null,null,2], distance = 3 Output: 1 Explanation: The only good pair is [2,5].
Constraints:
tree is in the range [1, 210].1 <= Node.val <= 1001 <= distance <= 10The key idea in #1530 Number of Good Leaf Nodes Pairs is to count pairs of leaf nodes whose shortest path distance is less than or equal to a given limit. Since the problem involves distances between leaves within a binary tree, a Depth-First Search (DFS) traversal works effectively.
During a postorder DFS, each node gathers distance information from its left and right subtrees. Instead of storing entire paths, the algorithm keeps track of the distance of leaf nodes from the current node. When both subtrees return distance lists, valid pairs can be counted by combining distances from the left and right sides whose sum does not exceed the allowed limit.
After counting valid pairs, the current node returns updated distances (incremented by one) to its parent. This bottom-up aggregation ensures that each leaf distance is only propagated up to the required depth. The approach efficiently processes each node once while limiting distance tracking, leading to a DFS-based solution with manageable time and space usage.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| DFS with distance aggregation | O(n * d^2) | O(h + d) |
Fraz
Use these hints if you're stuck. Try solving on your own first.
Start DFS from each leaf node. stop the DFS when the number of steps done > distance.
If you reach another leaf node within distance steps, add 1 to the answer.
Note that all pairs will be counted twice so divide the answer by 2.
This approach involves a DFS traversal of the tree. For each node, we compute the number of leaf nodes at each possible distance. We merge the results from the left and right subtrees and count the valid leaf pairs.
Time Complexity: O(n * distance) due to traversing the entire tree and computing leaf pairs.
Space Complexity: O(distance) for storing distance arrays.
1function TreeNode(val) {
2 this.val = val;
3 this.left = this.right = null;
4}
JavaScript similarly uses arrays to manage distances at each node. Each leaf node is managed with an individual distance array, allowing easy combination and analysis during traversal.
This approach leverages preprocessing leaf distances in a dynamic programming table, which gives quick lookups during pair evaluation. It builds the DP table during a DFS traversal, allowing efficient pair computation afterward.
Time Complexity: Approximately O(n^2) for thorough pairing and evaluation.
Space Complexity: O(n^2) due to pair-wise distance visualization.
1/* Like C, a C++ solution leverages advanced structures to track pair-wise leaf distance calculations efficiently within tree traversal. A rough sample plan provides guidance for completing a full solution. */Watch expert explanations and walkthroughs
Practice problems asked by these companies to ace your technical interviews.
Explore More ProblemsJot down your thoughts, approach, and key learnings
DFS is ideal because the solution requires processing child subtrees before evaluating the current node. A postorder traversal allows the algorithm to collect leaf distance information from both sides and count valid pairs at each step.
Yes, tree traversal and DFS-based problems like this are common in FAANG-style interviews. The problem tests understanding of binary trees, recursion, and how to aggregate information during postorder traversal.
The optimal approach uses a postorder DFS traversal. Each node collects distances of leaf nodes from its children and counts valid pairs whose combined distance does not exceed the limit. This bottom-up strategy avoids recomputing paths and keeps the solution efficient.
A binary tree combined with recursion and small distance arrays or lists works best. These structures help track leaf distances from each subtree and allow efficient pair comparisons at every node during DFS.
C++ can take advantage of STL and more sophisticated data management for calculating and preloading distances, easing evaluation processes.