You are given the head of a linked list with n nodes.
For each node in the list, find the value of the next greater node. That is, for each node, find the value of the first node that is next to it and has a strictly larger value than it.
Return an integer array answer where answer[i] is the value of the next greater node of the ith node (1-indexed). If the ith node does not have a next greater node, set answer[i] = 0.
Example 1:
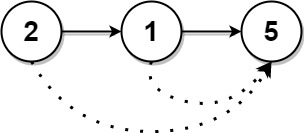
Input: head = [2,1,5] Output: [5,5,0]
Example 2:
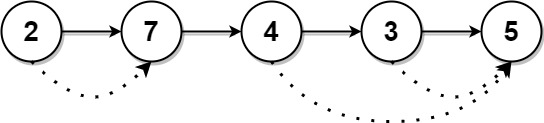
Input: head = [2,7,4,3,5] Output: [7,0,5,5,0]
Constraints:
n.1 <= n <= 1041 <= Node.val <= 109Problem Overview: You receive the head of a singly linked list. For every node, return the value of the next node to the right that has a strictly greater value. If no such node exists, return 0 for that position. The result is returned as an array aligned with the node order.
Approach 1: Monotonic Stack with Array Conversion (O(n) time, O(n) space)
Traverse the linked list once and copy all node values into an array. This converts the problem into the classic “next greater element” problem. Iterate through the array while maintaining a monotonic stack that stores indices of elements whose next greater value hasn't been found yet. When the current value is greater than the value at the stack's top index, pop that index and set its answer to the current value. Push the current index afterward. Each index is pushed and popped at most once, which guarantees O(n) time. This is the most common and interview-friendly solution.
Approach 2: Reverse Traversal with Stack (O(n) time, O(n) space)
Instead of processing from left to right, first convert the linked list into an array, then traverse it from right to left. Maintain a stack that keeps candidate values in decreasing order. For each element, pop all stack values less than or equal to the current value since they cannot be the next greater element. The remaining top of the stack is the next greater value. Record it and push the current value onto the stack. This approach still uses a stack but avoids storing indices. Time complexity remains O(n) and space complexity is O(n) for the stack and output.
Recommended for interviews: The monotonic stack approach is what interviewers typically expect. Converting the list to an array simplifies traversal and aligns with the standard “next greater element” pattern seen in many stack-based problems. Explaining the brute-force intuition (checking each node against all future nodes) shows understanding, but implementing the monotonic stack solution demonstrates mastery of linear-time optimization.
This approach leverages a monotonic stack to efficiently find the next greater element for each node in the linked list. By traversing the linked list once, we can maintain a stack to track potentially greater nodes and update results as we traverse.
This C solution uses an array-based stack to capture and process nodes from the linked list. As each node is encountered, it checks the stack for any nodes smaller than the current node. If found, it updates the result set. The code is efficient and operates in O(n) time complexity.
Time Complexity: O(n), where n is the length of the linked list, because each node is pushed and popped from the stack at most once.
Space Complexity: O(n), needed for storing the result and stack.
In this approach, reverse the linked list initially and then traverse, keeping track of the next greatest node using a stack. As this traversal is reversed, use a stack to efficiently find and keep the nearest greatest value.
In this approach, the linked list is reversed first. As we traverse from the new start, greater elements are stacked and compared for finding the next greater node. At the end, a final reversal of results provides the answer.
Time Complexity: O(n)
Space Complexity: O(n)
The problem requires finding the next larger node for each node in the linked list, that is, finding the first node to the right of each node in the linked list that is larger than it. We first traverse the linked list and store the values in the linked list in an array nums. For each element in the array nums, we just need to find the first element to its right that is larger than it. The problem of finding the next larger element can be solved using a monotonic stack.
We traverse the array nums from back to front, maintaining a stack stk that is monotonically decreasing from the bottom to the top. During the traversal, if the top element of the stack is less than or equal to the current element, we loop to pop the top element of the stack until the top element of the stack is larger than the current element or the stack is empty.
If the stack is empty at this time, it means that the current element does not have a next larger element, otherwise, the next larger element of the current element is the top element of the stack, and we update the answer array ans. Then we push the current element into the stack and continue the traversal.
After the traversal is over, we return the answer array ans.
The time complexity is O(n), and the space complexity is O(n). Where n is the length of the linked list.
Python
Java
C++
Go
TypeScript
Rust
JavaScript
| Approach | Complexity |
|---|---|
| Monotonic Stack Approach | Time Complexity: O(n), where n is the length of the linked list, because each node is pushed and popped from the stack at most once. |
| Reverse Traversal with Stack Approach | Time Complexity: O(n) |
| Monotonic Stack | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Brute Force Scan | O(n²) | O(1) | Good for explaining the basic idea or very small lists |
| Monotonic Stack with Array | O(n) | O(n) | Best general solution; standard next greater element pattern |
| Reverse Traversal with Stack | O(n) | O(n) | Useful when scanning from right and keeping decreasing stack of values |
LeetCode Next Greater Node In Linked List Solution Explained - Java • Nick White • 12,301 views views
Watch 9 more video solutions →Practice Next Greater Node In Linked List with our built-in code editor and test cases.
Practice on FleetCode