There exist two undirected trees with n and m nodes, labeled from [0, n - 1] and [0, m - 1], respectively.
You are given two 2D integer arrays edges1 and edges2 of lengths n - 1 and m - 1, respectively, where edges1[i] = [ai, bi] indicates that there is an edge between nodes ai and bi in the first tree and edges2[i] = [ui, vi] indicates that there is an edge between nodes ui and vi in the second tree.
Node u is target to node v if the number of edges on the path from u to v is even. Note that a node is always target to itself.
Return an array of n integers answer, where answer[i] is the maximum possible number of nodes that are target to node i of the first tree if you had to connect one node from the first tree to another node in the second tree.
Note that queries are independent from each other. That is, for every query you will remove the added edge before proceeding to the next query.
Example 1:
Input: edges1 = [[0,1],[0,2],[2,3],[2,4]], edges2 = [[0,1],[0,2],[0,3],[2,7],[1,4],[4,5],[4,6]]
Output: [8,7,7,8,8]
Explanation:
i = 0, connect node 0 from the first tree to node 0 from the second tree.i = 1, connect node 1 from the first tree to node 4 from the second tree.i = 2, connect node 2 from the first tree to node 7 from the second tree.i = 3, connect node 3 from the first tree to node 0 from the second tree.i = 4, connect node 4 from the first tree to node 4 from the second tree.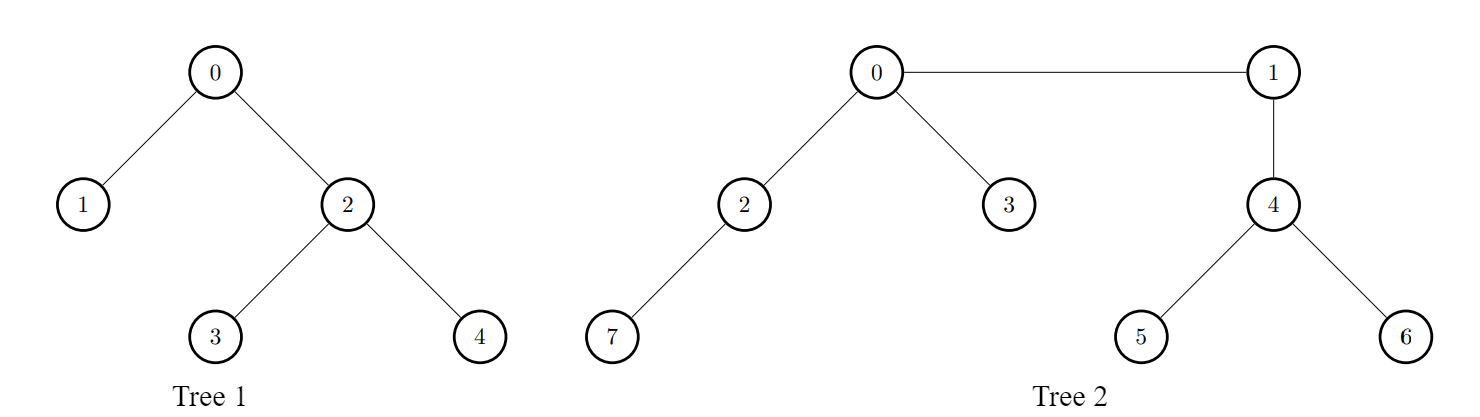
Example 2:
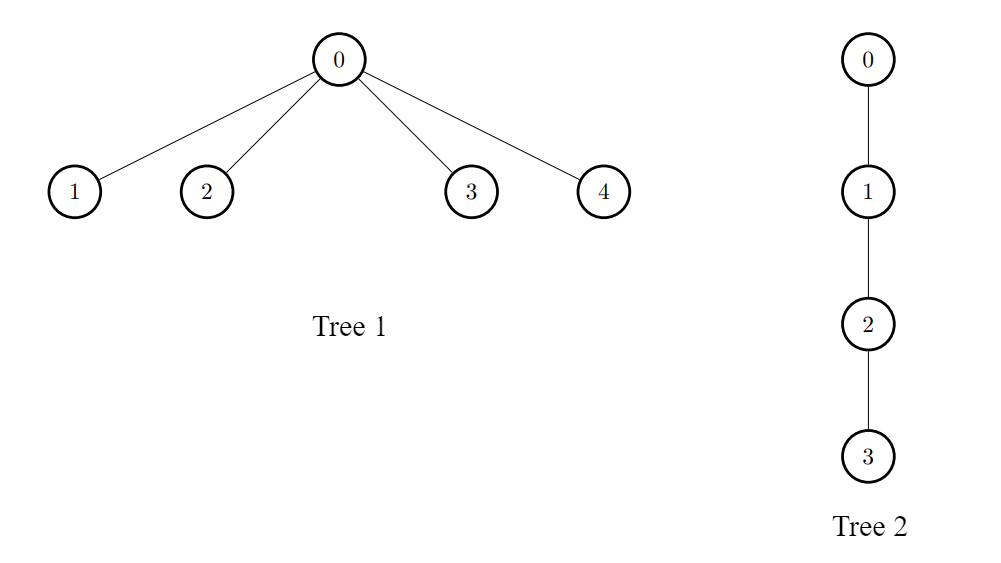
Input: edges1 = [[0,1],[0,2],[0,3],[0,4]], edges2 = [[0,1],[1,2],[2,3]]
Output: [3,6,6,6,6]
Explanation:
For every i, connect node i of the first tree with any node of the second tree.
Constraints:
2 <= n, m <= 105edges1.length == n - 1edges2.length == m - 1edges1[i].length == edges2[i].length == 2edges1[i] = [ai, bi]0 <= ai, bi < nedges2[i] = [ui, vi]0 <= ui, vi < medges1 and edges2 represent valid trees.In #3373 Maximize the Number of Target Nodes After Connecting Trees II, you are given two trees and must determine how to connect them so the number of valid target nodes is maximized. Because both structures are trees, an efficient solution relies on graph traversal and distance-based analysis.
A common strategy is to run DFS or BFS from each node to compute properties such as distance parity, reachable node counts, or other constraints that determine whether a node qualifies as a target. By preprocessing these values for both trees, you can evaluate how connecting a node from the first tree to one in the second tree affects the final count. Many optimized solutions store aggregated counts (for example by depth or parity) and reuse them instead of recomputing traversals.
The key idea is to precompute structural information for each tree and then combine the best possible connection efficiently. This avoids repeated traversals and keeps the algorithm scalable even for large trees.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| Tree traversal with preprocessing (DFS/BFS + aggregation) | O(n + m) | O(n + m) |
Ashish Pratap Singh
Use these hints if you're stuck. Try solving on your own first.
Compute an array <code>even</code> where <code>even[u]</code> is the number of nodes at an even distance from node <code>u</code>, for every <code>u</code> of the first tree.
Compute an array <code>odd</code> where <code>odd[u]</code> is the number of nodes at an odd distance from node <code>u</code>, for every <code>u</code> of the second tree.
<code>answer[i] = even[i]+ max(odd[1], odd[2], …, odd[m - 1])</code>
Watch expert explanations and walkthroughs
Jot down your thoughts, approach, and key learnings
Tree traversals such as DFS and BFS allow you to compute distances, depth levels, or other properties for each node. These computed values are then reused to determine how connecting two nodes from different trees influences the number of target nodes.
Hard tree and graph problems like this frequently appear in advanced coding interviews, especially at top tech companies. They test understanding of graph traversal, preprocessing techniques, and the ability to optimize repeated computations.
Adjacency lists are the most suitable structure for representing the trees. They allow efficient DFS or BFS traversal and make it easy to compute properties like depth, parent relationships, and counts of nodes that satisfy the target condition.
The optimal approach typically uses DFS or BFS to preprocess useful information for every node in each tree, such as distance parity or reachable counts. After preprocessing, you evaluate how connecting nodes from the two trees affects the total number of valid targets, allowing efficient computation without repeated traversals.