There exist two undirected trees with n and m nodes, with distinct labels in ranges [0, n - 1] and [0, m - 1], respectively.
You are given two 2D integer arrays edges1 and edges2 of lengths n - 1 and m - 1, respectively, where edges1[i] = [ai, bi] indicates that there is an edge between nodes ai and bi in the first tree and edges2[i] = [ui, vi] indicates that there is an edge between nodes ui and vi in the second tree. You are also given an integer k.
Node u is target to node v if the number of edges on the path from u to v is less than or equal to k. Note that a node is always target to itself.
Return an array of n integers answer, where answer[i] is the maximum possible number of nodes target to node i of the first tree if you have to connect one node from the first tree to another node in the second tree.
Note that queries are independent from each other. That is, for every query you will remove the added edge before proceeding to the next query.
Example 1:
Input: edges1 = [[0,1],[0,2],[2,3],[2,4]], edges2 = [[0,1],[0,2],[0,3],[2,7],[1,4],[4,5],[4,6]], k = 2
Output: [9,7,9,8,8]
Explanation:
i = 0, connect node 0 from the first tree to node 0 from the second tree.i = 1, connect node 1 from the first tree to node 0 from the second tree.i = 2, connect node 2 from the first tree to node 4 from the second tree.i = 3, connect node 3 from the first tree to node 4 from the second tree.i = 4, connect node 4 from the first tree to node 4 from the second tree.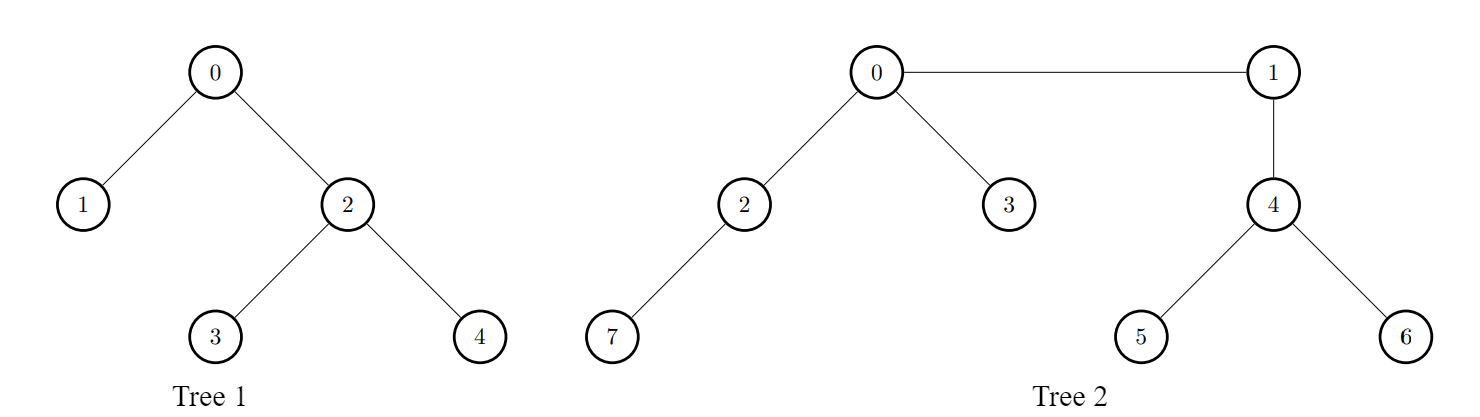
Example 2:
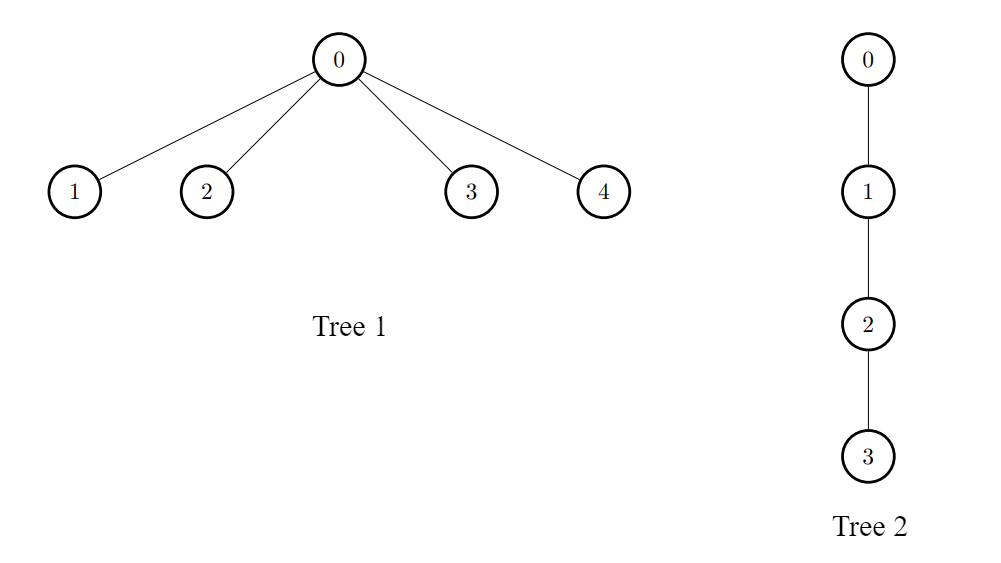
Input: edges1 = [[0,1],[0,2],[0,3],[0,4]], edges2 = [[0,1],[1,2],[2,3]], k = 1
Output: [6,3,3,3,3]
Explanation:
For every i, connect node i of the first tree with any node of the second tree.
Constraints:
2 <= n, m <= 1000edges1.length == n - 1edges2.length == m - 1edges1[i].length == edges2[i].length == 2edges1[i] = [ai, bi]0 <= ai, bi < nedges2[i] = [ui, vi]0 <= ui, vi < medges1 and edges2 represent valid trees.0 <= k <= 1000In #3372 Maximize the Number of Target Nodes After Connecting Trees I, you are given two trees and must determine how connecting them can maximize the number of target nodes reachable within a limited distance. The key idea is to leverage the tree structure and perform controlled distance exploration from each node.
A practical strategy is to run BFS or DFS from every node to count how many nodes fall within distance k. For nodes in the first tree, compute how many nodes are reachable within distance k. For nodes in the second tree, compute how many nodes are reachable within distance k-1, since one step will be used by the new connecting edge.
After preprocessing, store the best reachable count from the second tree and combine it with the counts from each node of the first tree. This avoids recomputing distances for every possible connection. The approach relies on repeated graph traversal and efficient aggregation of results.
Time complexity mainly depends on BFS/DFS runs across both trees, while space complexity comes from adjacency lists and traversal queues.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| BFS/DFS distance counting on both trees | O((n + m) * (n + m)) | O(n + m) |
Ashish Pratap Singh
Use these hints if you're stuck. Try solving on your own first.
For each node <code>u</code> in the first tree, find the number of nodes at a distance of at most <code>k</code> from node <code>u</code>.
For each node <code>v</code> in the second tree, find the number of nodes at a distance of at most <code>k - 1</code> from node <code>v</code>.
Watch expert explanations and walkthroughs
Jot down your thoughts, approach, and key learnings
When connecting two trees with a new edge, one step of the distance budget is used by that connecting edge. Therefore nodes in the second tree must be within k-1 distance from the chosen connection node to remain within the total limit.
Tree traversal and graph distance problems are very common in FAANG-style interviews. While this exact question may not always appear, the underlying techniques such as BFS, DFS, and distance-limited traversal are frequently tested.
Adjacency lists are the best structure for representing the trees efficiently. They allow fast traversal with BFS or DFS while keeping memory usage low for sparse tree graphs.
The common approach is to run BFS or DFS from each node to count how many nodes lie within distance k. By precomputing results for both trees and combining them strategically, you can determine the maximum number of target nodes after adding one connecting edge.