You are given the root of a binary tree with n nodes. Each node is assigned a unique value from 1 to n. You are also given an array queries of size m.
You have to perform m independent queries on the tree where in the ith query you do the following:
queries[i] from the tree. It is guaranteed that queries[i] will not be equal to the value of the root.Return an array answer of size m where answer[i] is the height of the tree after performing the ith query.
Note:
Example 1:
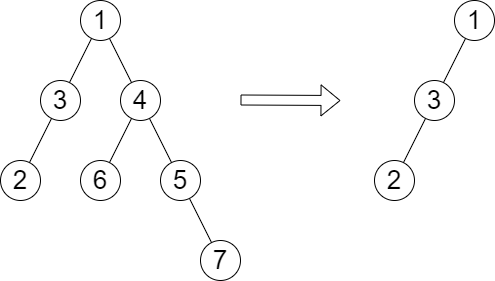
Input: root = [1,3,4,2,null,6,5,null,null,null,null,null,7], queries = [4] Output: [2] Explanation: The diagram above shows the tree after removing the subtree rooted at node with value 4. The height of the tree is 2 (The path 1 -> 3 -> 2).
Example 2:
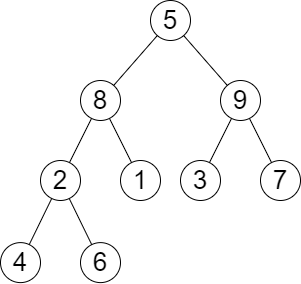
Input: root = [5,8,9,2,1,3,7,4,6], queries = [3,2,4,8] Output: [3,2,3,2] Explanation: We have the following queries: - Removing the subtree rooted at node with value 3. The height of the tree becomes 3 (The path 5 -> 8 -> 2 -> 4). - Removing the subtree rooted at node with value 2. The height of the tree becomes 2 (The path 5 -> 8 -> 1). - Removing the subtree rooted at node with value 4. The height of the tree becomes 3 (The path 5 -> 8 -> 2 -> 6). - Removing the subtree rooted at node with value 8. The height of the tree becomes 2 (The path 5 -> 9 -> 3).
Constraints:
n.2 <= n <= 1051 <= Node.val <= nm == queries.length1 <= m <= min(n, 104)1 <= queries[i] <= nqueries[i] != root.valIn #2458 Height of Binary Tree After Subtree Removal Queries, each query asks for the height of the remaining tree after removing the subtree rooted at a given node. Recomputing the height from scratch for every query would be inefficient, so the key idea is to preprocess the tree using depth-first search.
First, perform a DFS to compute the depth of each node and the height of its subtree. Next, run another traversal to determine the maximum possible height of the tree if a particular subtree is excluded. This can be done by propagating the best height achievable from parent paths or sibling subtrees (often called a rerooting or upward contribution technique).
By storing these precomputed values for every node, each query can be answered in O(1) time by simply returning the stored height after excluding that node's subtree. The preprocessing runs in O(n) time, making the total complexity efficient even for large numbers of queries.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| DFS Preprocessing with Rerooting Technique | O(n + q) | O(n) |
| Naive Recompute Height Per Query | O(n * q) | O(n) |
codestorywithMIK
Use these hints if you're stuck. Try solving on your own first.
Try pre-computing the answer for each node from 1 to n, and answer each query in O(1).
The answers can be precomputed in a single tree traversal after computing the height of each subtree.
The dynamic programming approach breaks the problem into smaller, more manageable sub-problems. We then solve each sub-problem once, store its result, and use these results to construct the solution to the original problem in an efficient manner, avoiding repeated calculations.
Time Complexity: O(n)
Space Complexity: O(n)
1#include <iostream>
2#include <vector>
3using namespace std;
4
5int fibonacci(int n) {
6 vector<int> dp(n + 1, 0);
7 dp[1] = dp[2] = 1;
8 for (int i = 3; i <= n; i++) {
9 dp[i] = dp[i - 1] + dp[i - 2];
10 }
11 return dp[n];
12}
13
14int main() {
int n = 10;
cout << "Fibonacci number is " << fibonacci(n) << endl;
return 0;
}This C++ solution uses a vector to store Fibonacci numbers, employing dynamic programming to efficiently calculate the nth Fibonacci number by reducing redundant calculations.
The recursive approach with memoization involves using a recursive function to calculate Fibonacci numbers and memorizing results of previously computed terms. It reduces the overhead of repeated computations by storing results in a data structure (e.g., dictionary).
Time Complexity: O(n)
Space Complexity: O(n) due to memoization array.
Watch expert explanations and walkthroughs
Practice problems asked by these companies to ace your technical interviews.
Explore More ProblemsJot down your thoughts, approach, and key learnings
Preprocessing avoids recomputing the tree height after every query. By calculating subtree heights and alternative heights ahead of time, each query can be answered instantly using stored values.
Yes, variations of tree rerooting, subtree removal effects, and height recalculation problems appear in FAANG-style interviews. They test understanding of DFS, tree dynamic programming, and efficient query handling.
A binary tree combined with arrays or hash maps for storing depth, subtree height, and precomputed results works best. These structures allow quick lookups during queries after the initial DFS preprocessing.
The optimal approach uses two DFS traversals with preprocessing. First compute subtree heights and node depths, then propagate the best possible height outside each subtree using a rerooting-style technique. This allows every query to be answered in constant time.
This recursive C solution uses an array for memoization to store already computed values, preventing recalculations and optimizing the Fibonacci computation.