You are given a doubly linked list, which contains nodes that have a next pointer, a previous pointer, and an additional child pointer. This child pointer may or may not point to a separate doubly linked list, also containing these special nodes. These child lists may have one or more children of their own, and so on, to produce a multilevel data structure as shown in the example below.
Given the head of the first level of the list, flatten the list so that all the nodes appear in a single-level, doubly linked list. Let curr be a node with a child list. The nodes in the child list should appear after curr and before curr.next in the flattened list.
Return the head of the flattened list. The nodes in the list must have all of their child pointers set to null.
Example 1:
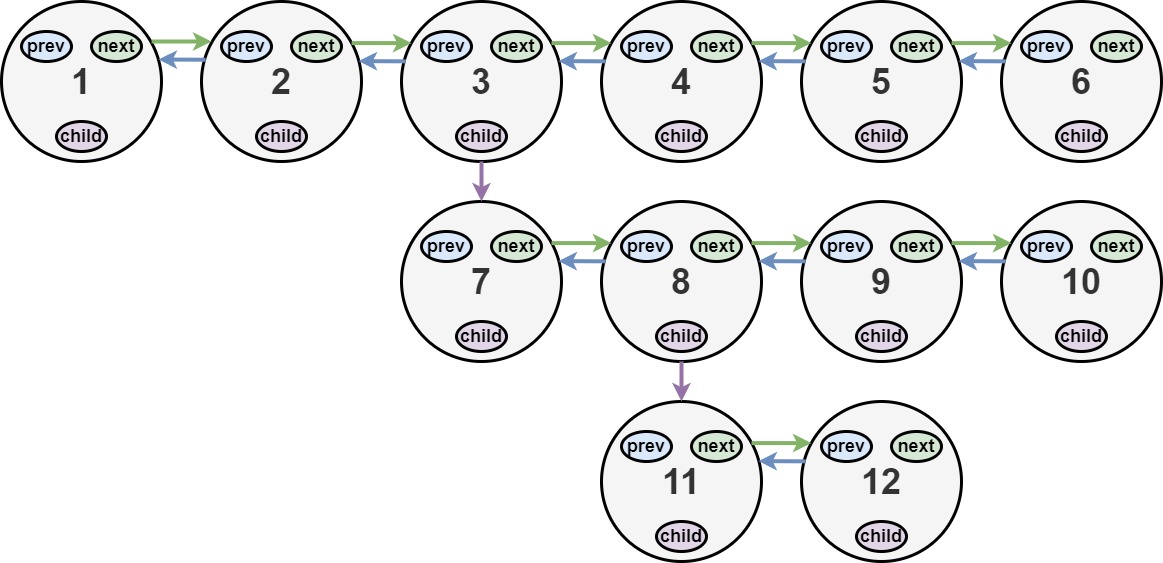
Input: head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12] Output: [1,2,3,7,8,11,12,9,10,4,5,6] Explanation: The multilevel linked list in the input is shown. After flattening the multilevel linked list it becomes:
Example 2:

Input: head = [1,2,null,3] Output: [1,3,2] Explanation: The multilevel linked list in the input is shown. After flattening the multilevel linked list it becomes: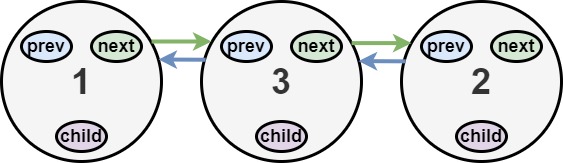
Example 3:
Input: head = [] Output: [] Explanation: There could be empty list in the input.
Constraints:
1000.1 <= Node.val <= 105How the multilevel linked list is represented in test cases:
We use the multilevel linked list from Example 1 above:
1---2---3---4---5---6--NULL
|
7---8---9---10--NULL
|
11--12--NULL
The serialization of each level is as follows:
[1,2,3,4,5,6,null] [7,8,9,10,null] [11,12,null]
To serialize all levels together, we will add nulls in each level to signify no node connects to the upper node of the previous level. The serialization becomes:
[1, 2, 3, 4, 5, 6, null]
|
[null, null, 7, 8, 9, 10, null]
|
[ null, 11, 12, null]
Merging the serialization of each level and removing trailing nulls we obtain:
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
The key idea in #430 Flatten a Multilevel Doubly Linked List is to convert a structure where nodes may contain a child pointer into a single-level doubly linked list while preserving the original order. A common strategy is to perform a Depth-First Search (DFS). When a node with a child is encountered, its child list is inserted between the node and its next pointer, and the algorithm continues traversing the child before returning to the original next node.
This can be implemented either recursively or using an explicit stack to simulate DFS traversal. During the process, pointers must be carefully updated so that prev and next links remain valid and the child pointer is cleared after flattening. The traversal ensures each node is processed exactly once. The overall approach runs in O(n) time because every node is visited once, while space depends on recursion depth or stack usage.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| Recursive DFS Flattening | O(n) | O(n) (recursion stack in worst case) |
| Iterative DFS Using Stack | O(n) | O(n) (explicit stack) |
NeetCode
In this approach, we utilize a stack to achieve depth-first traversal of the multilevel doubly linked list. We push nodes into the stack starting from the head, along with managing the child nodes as higher priority over next nodes. This ensures that we process all child nodes before moving on to the next nodes.
Time Complexity: O(n) where n is the number of nodes. Each node is visited once.
Space Complexity: O(n) for the stack in the worst case scenario.
1using System.Collections.Generic;
2
3public class Solution {
4 public Node Flatten(Node head) {
5 if (head == null) return head;
6
7 Stack<Node> stack = new Stack<Node>();
8 Node curr = head;
9
10 while (curr != null) {
11 if (curr.child != null) {
12 if (curr.next != null) stack.Push(curr.next);
13 curr.next = curr.child;
14 curr.child.prev = curr;
curr.child = null;
}
if (curr.next == null && stack.Count > 0) {
curr.next = stack.Pop();
if (curr.next != null) curr.next.prev = curr;
}
curr = curr.next;
}
return head;
}
}The C# version sticks to the iteration pattern via a stack and maintains the list flattening quite effectively using Language Integrated Query (LINQ) for stack operations.
This approach utilizes recursion to handle the traversing and flattening of lists. By inherently using the function call stack, it efficiently manages shifts between the parent and child lists, automatically flattening the entire structure as it recursively resolves each node and its children.
Time Complexity: O(n) due to the necessity to visit each node once.
Space Complexity: O(d) where d is the maximum depth of the children, necessitating stack space for recursion.
Watch expert explanations and walkthroughs
Practice problems asked by these companies to ace your technical interviews.
Explore More ProblemsJot down your thoughts, approach, and key learnings
DFS ensures that whenever a node has a child, the entire child list is processed before moving to the next node. This matches the required order of flattening where child nodes appear immediately after their parent node in the final list.
Yes, variations of multilevel linked list problems are asked in FAANG and other top tech company interviews. They test pointer manipulation, recursion, and understanding of DFS in linked structures.
A stack is commonly used to simulate DFS traversal in the iterative approach. It helps keep track of nodes that should be processed after finishing a child list. Alternatively, recursion can naturally perform the same DFS traversal.
The optimal approach uses Depth-First Search to traverse nodes and flatten child lists into the main doubly linked list. When a node has a child, the child list is inserted between the node and its next pointer. This ensures every node is processed once, giving O(n) time complexity.
The Python approach leverages recursion through 'flattenDFS' to break down the multilevel nodes into simpler, flat arrangements, dynamically patching lists together by handling next node linkage.