Design a Skiplist without using any built-in libraries.
A skiplist is a data structure that takes O(log(n)) time to add, erase and search. Comparing with treap and red-black tree which has the same function and performance, the code length of Skiplist can be comparatively short and the idea behind Skiplists is just simple linked lists.
For example, we have a Skiplist containing [30,40,50,60,70,90] and we want to add 80 and 45 into it. The Skiplist works this way:
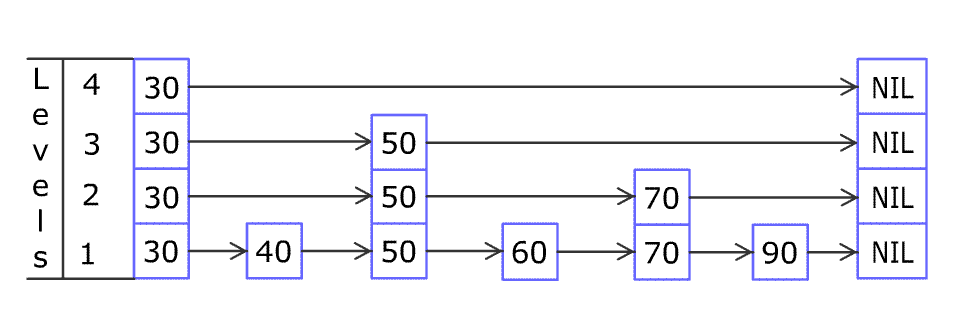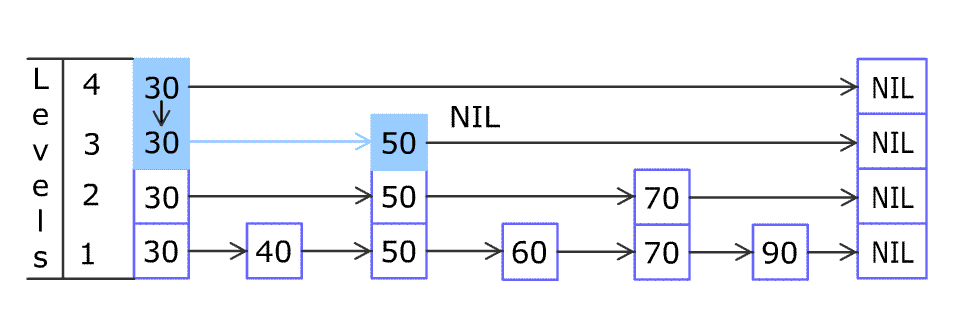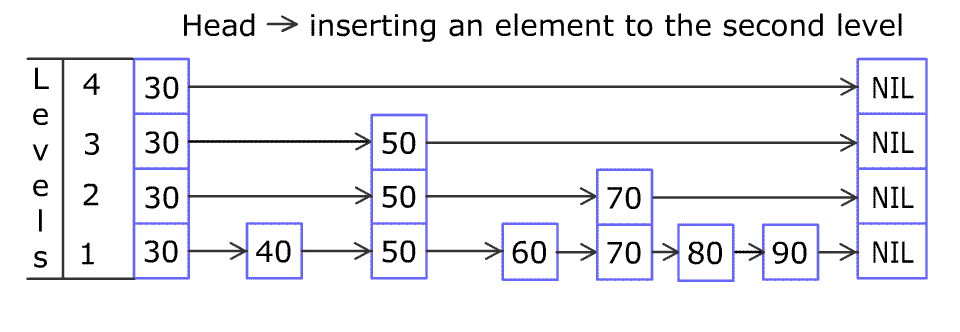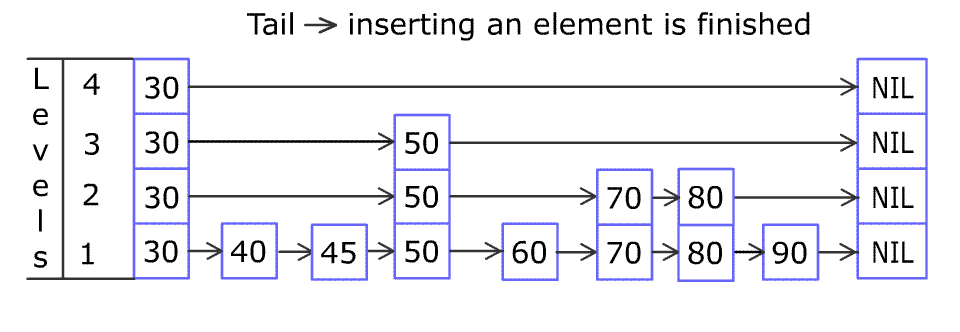
Artyom Kalinin [CC BY-SA 3.0], via Wikimedia Commons
You can see there are many layers in the Skiplist. Each layer is a sorted linked list. With the help of the top layers, add, erase and search can be faster than O(n). It can be proven that the average time complexity for each operation is O(log(n)) and space complexity is O(n).
See more about Skiplist: https://en.wikipedia.org/wiki/Skip_list
Implement the Skiplist class:
Skiplist() Initializes the object of the skiplist.bool search(int target) Returns true if the integer target exists in the Skiplist or false otherwise.void add(int num) Inserts the value num into the SkipList.bool erase(int num) Removes the value num from the Skiplist and returns true. If num does not exist in the Skiplist, do nothing and return false. If there exist multiple num values, removing any one of them is fine.Note that duplicates may exist in the Skiplist, your code needs to handle this situation.
Example 1:
Input ["Skiplist", "add", "add", "add", "search", "add", "search", "erase", "erase", "search"] [[], [1], [2], [3], [0], [4], [1], [0], [1], [1]] Output [null, null, null, null, false, null, true, false, true, false] Explanation Skiplist skiplist = new Skiplist(); skiplist.add(1); skiplist.add(2); skiplist.add(3); skiplist.search(0); // return False skiplist.add(4); skiplist.search(1); // return True skiplist.erase(0); // return False, 0 is not in skiplist. skiplist.erase(1); // return True skiplist.search(1); // return False, 1 has already been erased.
Constraints:
0 <= num, target <= 2 * 1045 * 104 calls will be made to search, add, and erase.Problem Overview: Design a data structure that supports search, add, and erase operations efficiently. The structure should behave like a balanced sorted list where operations run in logarithmic time on average.
Approach 1: Basic Level Implementation (O(n) search, O(n) space)
This approach builds a simplified skiplist using multiple linked lists stacked as levels. Each level skips over some nodes from the level below, but level promotion is handled manually rather than probabilistically. To search, you traverse horizontally until the next node exceeds the target, then drop down a level. Because balancing is not guaranteed, the structure can degrade and operations may reach O(n) time in the worst case. Useful for understanding how layered navigation works before introducing randomization.
Approach 2: Advanced Implementation with Probability Factor (Average O(log n) time, O(n) space)
This version introduces probabilistic balancing. When inserting a node, you repeatedly flip a virtual coin to decide how many levels the node should occupy. Higher levels contain fewer nodes, creating exponentially decreasing density. During search, you start from the highest level and move right while values are smaller than the target, dropping down levels when necessary. Random level assignment maintains balanced height statistically, giving average O(log n) search, insertion, and deletion.
Approach 3: Classic Skiplist with Random Levels (Average O(log n) time, O(n) space)
The classic skiplist maintains a head node with multiple forward pointers. Each inserted node receives a random level using geometric probability (commonly p = 0.5). During insertion, you track predecessor nodes at each level while traversing from the top layer downward. After generating the new node's level, you update forward pointers for all affected layers. This implementation closely follows the original skiplist design and provides efficient ordered operations comparable to balanced trees without complex rotations.
Approach 4: Deterministic Balanced Skiplist (O(log n) time, O(n) space)
A deterministic version removes randomness and enforces level structure using a fixed promotion rule. Nodes are promoted based on deterministic balancing criteria or fixed probability thresholds. When the structure becomes unbalanced, level reduction or restructuring keeps height near log n. This design improves predictability and avoids randomness while still maintaining fast navigation across layers. It is useful in environments where deterministic behavior is preferred.
Recommended for interviews: The classic probabilistic skiplist is what interviewers usually expect. Implementing random levels shows understanding of probabilistic balancing and layered traversal. The basic implementation helps explain the concept, but the optimized random-level design demonstrates stronger design skills and efficient use of linked list structures.
In the first approach, we'll implement a basic Skiplist with explicit support for multiple levels. Each node holds multiple forward pointers, one for each level, and we'll decide to promote nodes to higher levels based on a random mechanism.
The Skiplist maintains multiple levels in a hierarchical manner. Each element has a 50% chance to be promoted to the next level to efficiently handle search, insertion, and deletion operations.
This solution implements a Skiplist class using a head Node initialized with the maximum level of the Skiplist. The methods randomLevel, search, add, and erase utilize the structure's properties to efficiently handle elements.
1. search: Starts from the topmost level and moves laterally until the target is found or surpassed.
2. add: Uses an update array to keep track of pointers that need redirection upon adding a new node with a randomly assigned level.
3. erase: Similar to search, it finds the target node and adjusts the pointers to remove it if present.
Python
Time Complexity: O(log n) on average for search, add and erase operations.
Space Complexity: O(n), n being the number of elements in the Skiplist.
This approach further refines the previous implementation by introducing a configurable probability factor for determining node promotion to higher levels. This allows flexibility in tuning the space used versus time efficiency trade-offs.
This Java solution inculcates configurable probability support, influencing how frequently nodes are elevated up levels. The Skiplist class holds a constant probability P, tuned to the desired performance vs space trade-offs.
The rest of the structure and logic adhere similarly to the previous foundational approach but offers finer control over node promotions through the probabilistic function.
Java
Time Complexity: O(log n) on average for search, add and erase operations.
Space Complexity: O(n * log n), due to tower-like structure supporting flexible balancing.
This approach involves creating a skiplist using multiple levels of linked lists. Each element has a chance to appear in the higher-level lists. This approach gives an average time complexity of O(log n) for search, insert, and delete operations.
We use random coin flips (or a function) to determine the level of each new node. This randomness ensures the balance of the skiplist dynamically.
Steps:
This solution uses a Node class to represent each node in the skiplist and a Skiplist class to manage the operations. The random_level method randomly determines the level of each node, effectively balancing the skiplist by distributing nodes over multiple levels.
The search function looks for a given target by traversing from the topmost level down to level 0, taking advantage of the skiplist's structure to skip over large segments.
The add function not only inserts the new node at the found position but also handles node insertion at all appropriate levels according to the determined node level. The erase function removes the node if it exists, updating all pointers affected by the removal.
Time Complexity: For each operation (search, add, erase), the expected average time complexity is O(log n) because of the multi-level linked list design.
Space Complexity: O(n) because each node maintains up to a logarithmic number of pointers.
In this method, a deterministic approach is followed that emulates random choice but gives a semblance of control. Here, instead of true randomness, fixed levels for new nodes can be decided after every operation by ensuring a balance factor (based on a pre-defined coin probability) is maintained.
This approach ensures that skiplists retain efficient time complexity while assisting in balancing node distributions across levels.
This solution implements a Javascript skiplist utilizing a Node class with array-based forward pointers. The skiplist operations manipulate the pointers strategically, following a fixed structure for level determination maintained by rehashed 'random' probabilities.
It effectively handles search, insert, and removal operations while maintaining overall balance across levels under deterministic configurations.
JavaScript
C#
Time Complexity: Each main operation is justified through steps averaging complexity limited by the log scale of maximum elements, maintaining average O(log n) efficiency.
Space Complexity: The space, predominantly used for structure maintenance in nodes, fits within an O(n) bound.
The core idea of a skip list is to use multiple "levels" to store data, with each level acting as an index. Data starts from the bottom level linked list and gradually rises to higher levels, eventually forming a multi-level linked list structure. Each level's nodes only contain part of the data, allowing for jumps to reduce search time.
In this problem, we use a Node class to represent the nodes of the skip list. Each node contains a val field and a next array. The length of the array is level, indicating the next node at each level. We use a Skiplist class to implement the skip list operations.
The skip list contains a head node head and the current maximum level level. The head node's value is set to -1 to mark the starting position of the list. We use a dynamic array next to store pointers to successor nodes.
For the search operation, we start from the highest level of the skip list and traverse downwards until we find the target node or determine that the target node does not exist. At each level, we use the find_closest method to jump to the node closest to the target.
For the add operation, we first randomly decide the level of the new node. Then, starting from the highest level, we find the node closest to the new value at each level and insert the new node at the appropriate position. If the level of the inserted node is greater than the current maximum level of the skip list, we need to update the level of the skip list.
For the erase operation, similar to the search operation, we traverse each level of the skip list to find and delete the target node. When deleting a node, we need to update the next pointers at each level. If the highest level of the skip list has no nodes, we need to decrease the level of the skip list.
Additionally, we define a random_level method to randomly decide the level of the new node. This method generates a random number between [1, max_level] until the generated random number is greater than or equal to p. We also have a find_closest method to find the node closest to the target value at each level.
The time complexity of the above operations is O(log n), where n is the number of nodes in the skip list. The space complexity is O(n).
Python
Java
C++
Go
TypeScript
| Approach | Complexity |
|---|---|
| Approach 1: Basic Level Implementation | Time Complexity: O(log n) on average for search, add and erase operations. Space Complexity: O(n), n being the number of elements in the Skiplist. |
| Approach 2: Advanced Level Implementation with Probability Factor | Time Complexity: O(log n) on average for search, add and erase operations. Space Complexity: O(n * log n), due to tower-like structure supporting flexible balancing. |
| Approach 1: Classic Skiplist Implementation with Random Levels | Time Complexity: For each operation (search, add, erase), the expected average time complexity is O(log n) because of the multi-level linked list design. Space Complexity: O(n) because each node maintains up to a logarithmic number of pointers. |
| Approach 2: Deterministic Balanced Skiplist with Fixed Coin Probability and Level Reduction | Time Complexity: Each main operation is justified through steps averaging complexity limited by the log scale of maximum elements, maintaining average O(log n) efficiency. Space Complexity: The space, predominantly used for structure maintenance in nodes, fits within an O(n) bound. |
| Data Structure | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Basic Level Implementation | O(n) | O(n) | Learning the layered linked-list concept before adding probabilistic balancing |
| Advanced Probability-Based Skiplist | O(log n) average | O(n) | General implementation where probabilistic balancing keeps operations fast |
| Classic Random Level Skiplist | O(log n) average | O(n) | Most common interview implementation matching original skiplist design |
| Deterministic Balanced Skiplist | O(log n) | O(n) | Systems requiring predictable structure without randomness |
花花酱 LeetCode 1206. Design Skiplist - 刷题找工作 EP367 • Hua Hua • 3,955 views views
Watch 8 more video solutions →Practice Design Skiplist with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor