You are given a n x n 2D array grid containing distinct elements in the range [0, n2 - 1].
Implement the NeighborSum class:
NeighborSum(int [][]grid) initializes the object.int adjacentSum(int value) returns the sum of elements which are adjacent neighbors of value, that is either to the top, left, right, or bottom of value in grid.int diagonalSum(int value) returns the sum of elements which are diagonal neighbors of value, that is either to the top-left, top-right, bottom-left, or bottom-right of value in grid.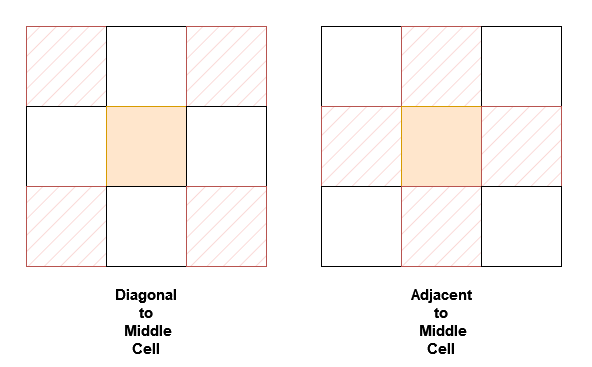
Example 1:
Input:
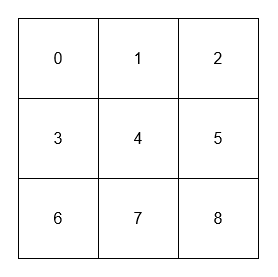
["NeighborSum", "adjacentSum", "adjacentSum", "diagonalSum", "diagonalSum"]
[[[[0, 1, 2], [3, 4, 5], [6, 7, 8]]], [1], [4], [4], [8]]
Output: [null, 6, 16, 16, 4]
Explanation:
Example 2:
Input:
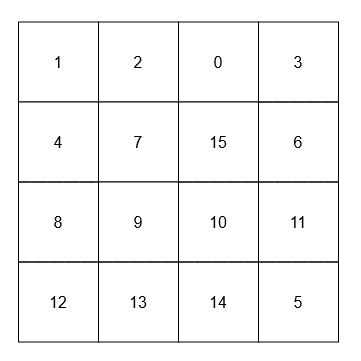
["NeighborSum", "adjacentSum", "diagonalSum"]
[[[[1, 2, 0, 3], [4, 7, 15, 6], [8, 9, 10, 11], [12, 13, 14, 5]]], [15], [9]]
Output: [null, 23, 45]
Explanation:
Constraints:
3 <= n == grid.length == grid[0].length <= 100 <= grid[i][j] <= n2 - 1grid[i][j] are distinct.value in adjacentSum and diagonalSum will be in the range [0, n2 - 1].2 * n2 calls will be made to adjacentSum and diagonalSum.The key idea in #3242 Design Neighbor Sum Service is to efficiently locate a value in a matrix and compute the sum of its surrounding neighbors. Since the service may be queried multiple times, repeatedly scanning the matrix would be inefficient. A better strategy is to preprocess the matrix during initialization.
Use a hash table (or map) that stores each value's coordinates in the grid. This allows constant-time lookup of the cell position for any queried value. Once the row and column are known, you can easily check its neighboring cells such as (r±1, c), (r, c±1) for adjacent neighbors or (r±1, c±1) for diagonal neighbors, while ensuring indices stay within matrix bounds.
This design converts each query into a simple simulation step over a few fixed directions. With the coordinate map, lookup becomes O(1), and neighbor checks are also constant. The preprocessing step builds the map once using the input matrix.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| Preprocess with Hash Map + Neighbor Simulation | Initialization: O(n^2), Query: O(1) | O(n^2) |
stoney codes
Use these hints if you're stuck. Try solving on your own first.
Find the cell <code>(i, j)</code> in which the element is present.
You can store the coordinates for each value.
Watch expert explanations and walkthroughs
Jot down your thoughts, approach, and key learnings
Problems involving matrix traversal, hashing, and system-style design are common in FAANG interviews. While this exact question may vary, the underlying concepts such as hash maps and grid simulations are frequently tested.
Preprocessing stores value-to-position mappings so each query can directly access the relevant cell. Without preprocessing, every query would require scanning the entire matrix, increasing the time complexity significantly.
A hash table (map) is the most effective data structure because it maps each matrix value to its row and column index. This avoids repeatedly scanning the matrix when handling multiple queries.
The optimal approach is to preprocess the matrix and store each value's coordinates in a hash map. This allows constant-time lookup of a cell's position and enables quick calculation of adjacent or diagonal neighbor sums.