A linked list of length n is given such that each node contains an additional random pointer, which could point to any node in the list, or null.
Construct a deep copy of the list. The deep copy should consist of exactly n brand new nodes, where each new node has its value set to the value of its corresponding original node. Both the next and random pointer of the new nodes should point to new nodes in the copied list such that the pointers in the original list and copied list represent the same list state. None of the pointers in the new list should point to nodes in the original list.
For example, if there are two nodes X and Y in the original list, where X.random --> Y, then for the corresponding two nodes x and y in the copied list, x.random --> y.
Return the head of the copied linked list.
The linked list is represented in the input/output as a list of n nodes. Each node is represented as a pair of [val, random_index] where:
val: an integer representing Node.valrandom_index: the index of the node (range from 0 to n-1) that the random pointer points to, or null if it does not point to any node.Your code will only be given the head of the original linked list.
Example 1:
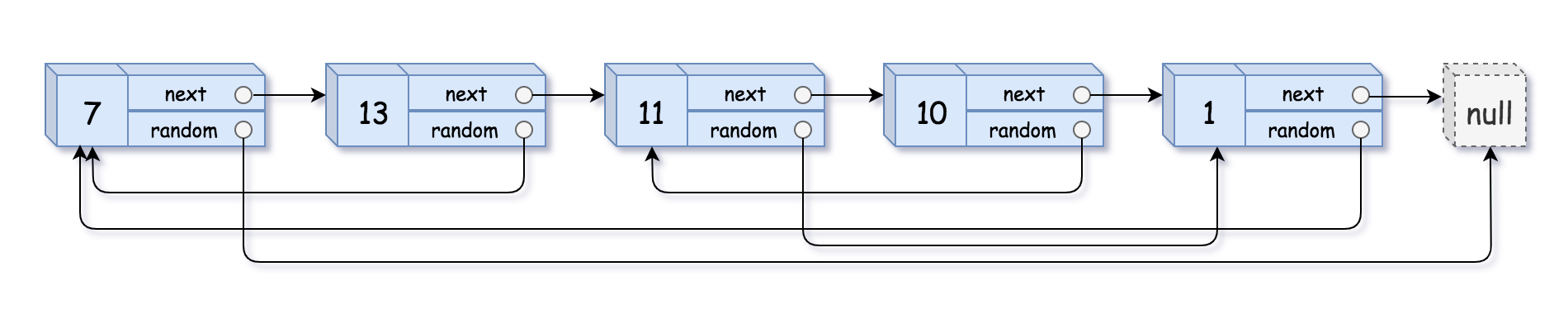
Input: head = [[7,null],[13,0],[11,4],[10,2],[1,0]] Output: [[7,null],[13,0],[11,4],[10,2],[1,0]]
Example 2:

Input: head = [[1,1],[2,1]] Output: [[1,1],[2,1]]
Example 3:

Input: head = [[3,null],[3,0],[3,null]] Output: [[3,null],[3,0],[3,null]]
Constraints:
0 <= n <= 1000-104 <= Node.val <= 104Node.random is null or is pointing to some node in the linked list.The main challenge in #138 Copy List with Random Pointer is duplicating a linked list where each node has both a next pointer and a random pointer that may reference any node in the list. A common strategy is to use a hash table to map each original node to its copied counterpart. In the first pass, create new nodes and store the mapping. In the second pass, correctly assign the next and random pointers using the stored references.
An alternative optimized technique interweaves copied nodes directly within the original list, allowing you to derive the correct random links without extra storage. After assigning pointers, the two lists are separated. The hash map approach is easier to reason about, while the interweaving method improves space efficiency. Both approaches typically run in O(n) time, with space complexity depending on the method used.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| Hash Map Mapping | O(n) | O(n) |
| Interweaving Nodes (Optimized) | O(n) | O(1) |
NeetCode
Use these hints if you're stuck. Try solving on your own first.
Just iterate the linked list and create copies of the nodes on the go. Since a node can be referenced from multiple nodes due to the random pointers, ensure you are not making multiple copies of the same node.
You may want to use extra space to keep old_node ---> new_node mapping to prevent creating multiple copies of the same node.
We can avoid using extra space for old_node ---> new_node mapping by tweaking the original linked list. Simply interweave the nodes of the old and copied list. For example: Old List: A --> B --> C --> D InterWeaved List: A --> A' --> B --> B' --> C --> C' --> D --> D'
The interweaving is done using next</b> pointers and we can make use of interweaved structure to get the correct reference nodes for random</b> pointers.
This approach involves using a hash map to build a one-to-one mapping from the original list nodes to the copied list nodes. The algorithm consists of the following main steps:
next chain of the deep copy, while storing the mapping of original nodes to copied nodes in a hash map.random pointers in the copied list by referring back to the original nodes' random pointers.Time Complexity: O(n), where n is the number of nodes in the linked list, because we pass through the list twice.
Space Complexity: O(n) due to the use of a dictionary that stores mappings for each node.
1class Node:
2 def __init__(self, val=0, next=None, random=None):
3 self.val = val
4 self.next = next
5 self.random = random
6
7class Solution:
8 def copyRandomList(self, head: 'Node') -> 'Node':
9 if not head:
10 return None
11 # Create a dictionary to map old nodes to new nodes
12 old_to_new = {}
13
14 # First pass: copy nodes and store mapping in hash map
15 current = head
16 while current:
17 clone = Node(current.val)
18 old_to_new[current] = clone
19 current = current.next
20
21 # Second pass: assign next and random pointers
22 current = head
23 while current:
24 if current.next:
25 old_to_new[current].next = old_to_new[current.next]
26 if current.random:
27 old_to_new[current].random = old_to_new[current.random]
28 current = current.next
29
30 return old_to_new[head]The solution uses a two-pass algorithm:
next and random linkages.next and random pointers for the copied nodes. These are set using the previously built dictionary.This approach involves interleaving the cloned nodes with original ones in the same list. The three main steps include:
Time Complexity: O(n) as we traverse the list three times independently.
Space Complexity: O(1) as we only use a few additional pointers and no extra data structures.
1function Node(val, next, random) {
2 this.
This approach involves using a hash map to keep track of the relationship between the original nodes and their corresponding nodes in the copied list. First, traverse the original linked list to create a copy of each node, while storing the mapping from original nodes to copied nodes. In the second pass, assign the 'next' and 'random' pointers in the copied list based on this mapping.
Time Complexity: O(n), where n is the number of nodes in the linked list. We traverse the list twice.
Space Complexity: O(n) due to the auxiliary space used by the hash map.
This approach involves interleaving the copied nodes with the original nodes in the list. By placing each copied node immediately after its original node, the 'random' pointers can be easily assigned by looking at the 'random' pointers of the original nodes. Finally, the original and copied nodes are separated to complete the process.
Time Complexity: O(n), as we traverse the list a few times but each operation is linear.
Space Complexity: O(1), since no additional data structures are used apart from constant space variables.
public:
int val;
Node* next;
Node* random;
Node(int _val) : val(_val), next(NULL), random(NULL) {}
};
class Solution {
public:
Node* copyRandomList(Node* head) {
if (!head) return nullptr;
Node* current = head;
// Step 1: Duplicate nodes interleaved
while (current) {
Node* copy = new Node(current->val);
copy->next = current->next;
current->next = copy;
current = copy->next;
}
// Step 2: Assign random pointers to the copied nodes
current = head;
while (current) {
current->next->random = current->random ? current->random->next : nullptr;
current = current->next->next;
}
// Step 3: Detach the duplicated list from the original
Node* copyHead = head->next;
Node* copyCurrent = copyHead;
current = head;
while (current) {
current->next = current->next->next;
copyCurrent->next = copyCurrent->next ? copyCurrent->next->next : nullptr;
current = current->next;
copyCurrent = copyCurrent->next;
}
return copyHead;
}
};Watch expert explanations and walkthroughs
Practice problems asked by these companies to ace your technical interviews.
Explore More ProblemsJot down your thoughts, approach, and key learnings
The difficulty comes from correctly replicating the random pointers that can point to any node or null. Unlike normal linked list cloning, you must maintain correct references between original and copied nodes. Handling these relationships efficiently requires careful pointer management.
Yes, this problem is frequently discussed in technical interview preparation and has appeared in interviews at large tech companies. It tests knowledge of linked lists, pointer manipulation, and space optimization techniques. Interviewers often expect candidates to explain both the hash map and optimized approaches.
A popular optimal approach interweaves copied nodes directly within the original linked list. This allows the algorithm to assign random pointers without using extra memory for mapping. After pointers are set, the copied list is separated, achieving O(n) time and O(1) extra space.
A hash table is commonly used to map each original node to its cloned node. This structure makes it easy to assign both next and random pointers during a second traversal. While it uses extra space, it simplifies the implementation.
The solution works in three main phases:
next pointer is redirected to its clone, and the clone points to the following original node.next pointers to point to the original list and cloned list separately.The solution involves creating a deep copy of each node and storing the original-to-copy mappings in a hash map. After creating the copies, the 'next' and 'random' pointers for each copied node are assigned using the hash map. This ensures that the structure of the new list mirrors the original.
This C++ version uses a similar method: interleaving the original and copied nodes to simplify the reassignment of 'random' pointers. After interlinking and setting pointers, it detaches the copy list to form an independent deep copy.