Given a reference of a node in a connected undirected graph.
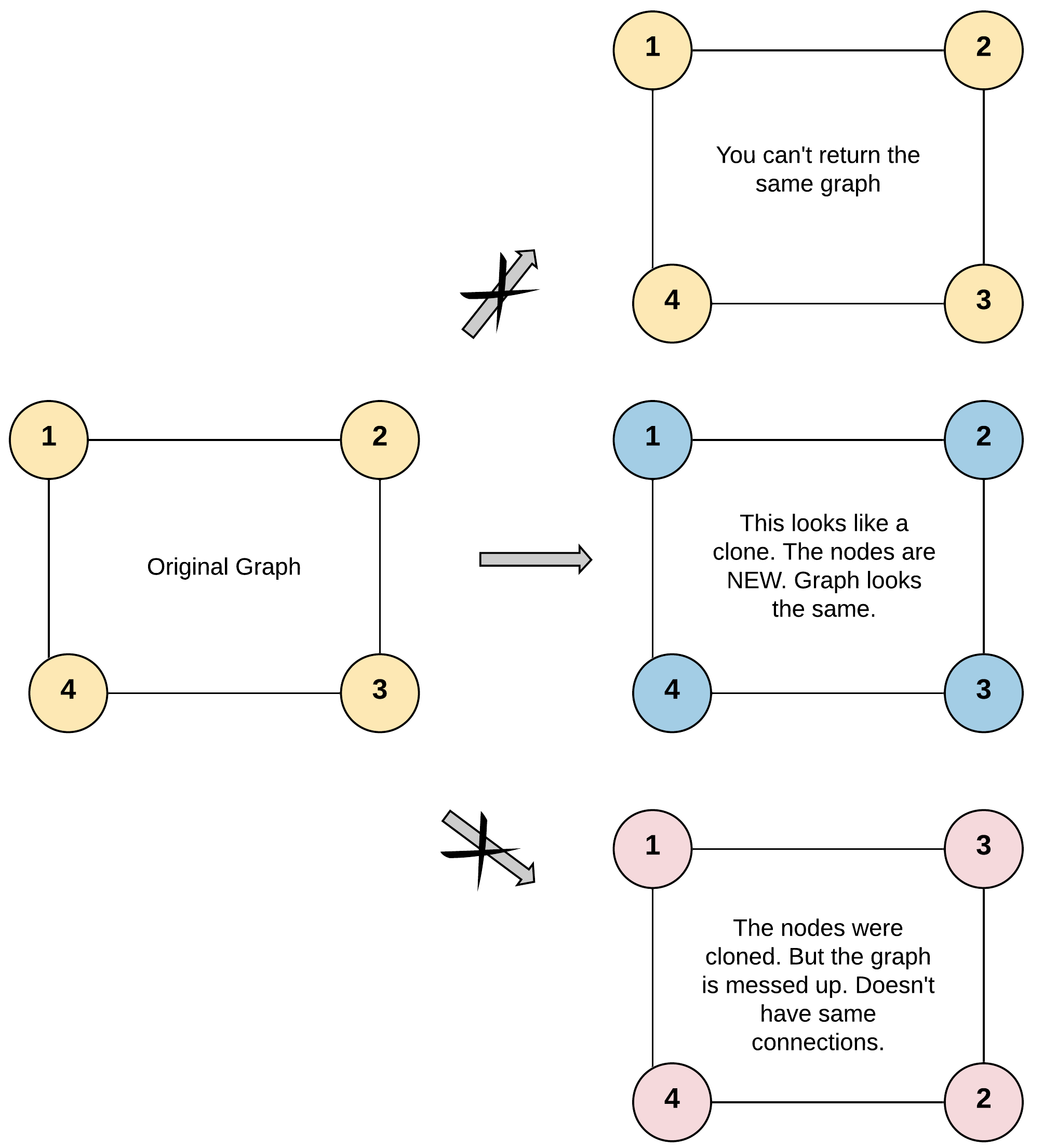
Return a deep copy (clone) of the graph.
Each node in the graph contains a value (int) and a list (List[Node]) of its neighbors.
class Node {
public int val;
public List<Node> neighbors;
}
Test case format:
For simplicity, each node's value is the same as the node's index (1-indexed). For example, the first node with val == 1, the second node with val == 2, and so on. The graph is represented in the test case using an adjacency list.
An adjacency list is a collection of unordered lists used to represent a finite graph. Each list describes the set of neighbors of a node in the graph.
The given node will always be the first node with val = 1. You must return the copy of the given node as a reference to the cloned graph.
Example 1:
Input: adjList = [[2,4],[1,3],[2,4],[1,3]] Output: [[2,4],[1,3],[2,4],[1,3]] Explanation: There are 4 nodes in the graph. 1st node (val = 1)'s neighbors are 2nd node (val = 2) and 4th node (val = 4). 2nd node (val = 2)'s neighbors are 1st node (val = 1) and 3rd node (val = 3). 3rd node (val = 3)'s neighbors are 2nd node (val = 2) and 4th node (val = 4). 4th node (val = 4)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
Example 2:
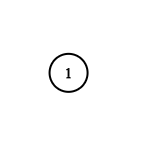
Input: adjList = [[]] Output: [[]] Explanation: Note that the input contains one empty list. The graph consists of only one node with val = 1 and it does not have any neighbors.
Example 3:
Input: adjList = [] Output: [] Explanation: This an empty graph, it does not have any nodes.
Constraints:
[0, 100].1 <= Node.val <= 100Node.val is unique for each node.The key idea in #133 Clone Graph is to create a deep copy of every node and its connections in an undirected graph. Since graphs may contain cycles, you must avoid recreating the same node multiple times. The most effective strategy is to use a Hash Map that maps each original node to its cloned counterpart.
You can traverse the graph using either Depth-First Search (DFS) or Breadth-First Search (BFS). When visiting a node for the first time, create its clone and store it in the map. For each neighbor, recursively or iteratively process it and connect the cloned neighbor to the cloned node using clone.neighbors.
The hash map ensures that if a node is encountered again due to cycles or multiple paths, the already-created clone is reused. This prevents infinite loops and guarantees a correct deep copy. Both DFS and BFS approaches traverse every node and edge once, leading to efficient performance.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| Depth-First Search (DFS) | O(V + E) | O(V) |
| Breadth-First Search (BFS) | O(V + E) | O(V) |
NeetCode
The Depth-First Search (DFS) approach is one of the most intuitive ways to solve the graph cloning problem. Here, we will recursively explore each node starting from the root (Node 1) and keep a map to store already cloned nodes, ensuring each node is cloned once.
For each node, we:
Time Complexity: O(V+E), where V is the number of vertices and E is the number of edges. This is because we visit each node and edge once.
Space Complexity: O(V), for the recursion stack and the clone map.
1import java.util.*;
2
3class Node {
4 public int val;
5 public
The Java solution involves using a HashMap to track visited nodes. cloneGraph recursively clones each node and its neighbors if not already cloned, ensuring that each node is processed once.
An alternative approach is to use Breadth-First Search (BFS), which is iterative in nature. Here, we utilize a queue to help explore each node level by level, preventing deep recursion and managing each node's clone in a breadth-wise manner.
In this BFS approach:
Time Complexity: O(V+E).
Space Complexity: O(V).
1#include <unordered_map>
#include <queue>
using namespace std;
class Node {
public:
int val;
vector<Node*> neighbors;
Node() {
val = 0;
neighbors = vector<Node*>();
}
Node(int _val) {
val = _val;
neighbors = vector<Node*>();
}
Node(int _val, vector<Node*> _neighbors) {
val = _val;
neighbors = _neighbors;
}
};
class Solution {
public:
Node* cloneGraph(Node* node) {
if (!node) return NULL;
unordered_map<Node*, Node*> visited;
queue<Node*> q;
q.push(node);
visited[node] = new Node(node->val);
while (!q.empty()) {
auto n = q.front(); q.pop();
for (auto neighbor : n->neighbors) {
if (visited.find(neighbor) == visited.end()) {
visited[neighbor] = new Node(neighbor->val);
q.push(neighbor);
}
visited[n]->neighbors.push_back(visited[neighbor]);
}
}
return visited[node];
}
};Watch expert explanations and walkthroughs
Practice problems asked by these companies to ace your technical interviews.
Explore More ProblemsJot down your thoughts, approach, and key learnings
Yes, Clone Graph is a common graph problem frequently asked in FAANG and other top tech company interviews. It tests understanding of graph traversal, hash maps, and handling cycles in graph structures.
The optimal approach uses either DFS or BFS combined with a hash map that maps original nodes to their cloned copies. This ensures each node is cloned only once and prevents infinite loops caused by cycles in the graph.
Yes, Clone Graph can be solved using both BFS and DFS. BFS typically uses a queue for traversal, while DFS uses recursion or a stack, but both approaches rely on a hash map to track cloned nodes.
A hash map is essential for storing the relationship between original nodes and their cloned versions. It helps quickly check if a node has already been copied and allows you to correctly reconstruct neighbor relationships.
This C++ BFS-based solution utilizes a queue to explore nodes level by level. We maintain a map visited to keep track of the original to clone node mapping. Each node and its neighbors are iteratively visited, cloned, and linked.