Given the root of a binary tree, return the postorder traversal of its nodes' values.
Example 1:
Input: root = [1,null,2,3]
Output: [3,2,1]
Explanation:
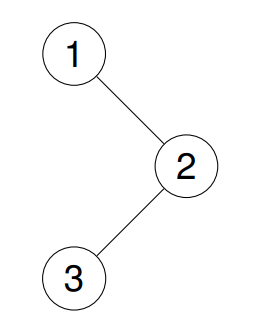
Example 2:
Input: root = [1,2,3,4,5,null,8,null,null,6,7,9]
Output: [4,6,7,5,2,9,8,3,1]
Explanation:
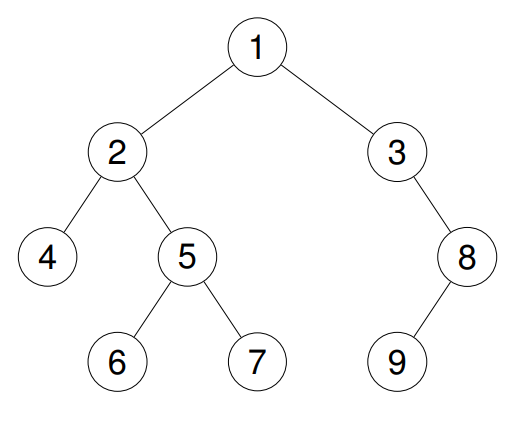
Example 3:
Input: root = []
Output: []
Example 4:
Input: root = [1]
Output: [1]
Constraints:
[0, 100].-100 <= Node.val <= 100The goal of Binary Tree Postorder Traversal is to visit nodes in the order left → right → root. This traversal naturally fits a Depth-First Search (DFS) strategy. The most intuitive approach is recursive DFS, where you recursively process the left subtree, then the right subtree, and finally record the current node's value. This mirrors the definition of postorder traversal and is easy to implement.
An alternative is an iterative solution using a stack. Because postorder requires processing the root after its children, the stack helps simulate recursion while tracking nodes that still need their right subtree processed. Some variations also use two stacks or reverse a modified preorder traversal.
In both approaches, every node is visited exactly once, giving a time complexity of O(n). The space complexity depends on the tree height due to recursion stack or explicit stack usage, which is O(h) in the average case and up to O(n) for skewed trees.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| Recursive DFS | O(n) | O(h) |
| Iterative Stack-Based Traversal | O(n) | O(h) |
NeetCode
The simplest way to perform a postorder traversal of a binary tree is recursively. In postorder traversal, you need to traverse the left subtree, then traverse the right subtree, finally visit the root node. This means visiting the left child, then the right child, and then the node itself for each node in the tree.
Time Complexity: O(n), where n is the number of nodes in the binary tree, because each node is visited once.
Space Complexity: O(h), where h is the height of the tree, due to recursive call stack usage.
1#include <vector>
2using namespace std;
3
4struct TreeNode {
5 int val;
6 TreeNode *left;
7 TreeNode *right;
8 TreeNode(int x) : val(x), left(NULL), right(NULL) {}
9};
10
11void postorderHelper(TreeNode* root, vector<int>& result) {
12 if (root == nullptr) return;
13 postorderHelper(root->left, result);
14 postorderHelper(root->right, result);
result.push_back(root->val);
}
vector<int> postorderTraversal(TreeNode* root) {
vector<int> result;
postorderHelper(root, result);
return result;
}This C++ solution involves a recursive helper method, postorderHelper, to carry out postorder traversal on the binary tree. It pushes values into a vector once both the left and right subtrees are traversed. Thus ensuring the nodes are traversed in postorder: left-right-root.
To perform postorder traversal iteratively, two stacks can be used. The first stack is used to perform a modified preorder traversal (root-right-left), while the second stack reverses this order to provide the postorder traversal (left-right-root). This approach allows the sequence of visiting nodes in postorder traversal without recursion.
Time Complexity: O(n) where n is the number of nodes.
Space Complexity: O(n) due to the usage of two stacks, each containing n nodes in the worst case for balanced or full trees.
Watch expert explanations and walkthroughs
Practice problems asked by these companies to ace your technical interviews.
Explore More ProblemsJot down your thoughts, approach, and key learnings
Postorder traversal is useful when operations must be performed after processing both children, such as deleting a tree or evaluating expression trees. Since child nodes are processed before the parent, dependencies are handled naturally.
Yes, binary tree traversal problems are very common in FAANG-style interviews. Postorder traversal often appears directly or as part of larger problems like tree evaluation, serialization, or subtree processing.
A stack is the most useful data structure for iterative postorder traversal because it simulates the function call stack used in recursion. It helps track nodes whose right subtree still needs to be processed.
The most common approach is recursive DFS, where you traverse the left subtree, then the right subtree, and finally process the root. It is simple, intuitive, and runs in O(n) time. An iterative stack-based approach can also be used when recursion is not preferred.
This JavaScript solution circumvents recursion by employing two stacks to process the tree. The initial stack (stack1) uses root-right-left sequence collecting nodes, which are subsequently popped from stack2 in reversed order to deliver a left-right-root traversal sequence.