Given the head of a sorted linked list, delete all duplicates such that each element appears only once. Return the linked list sorted as well.
Example 1:
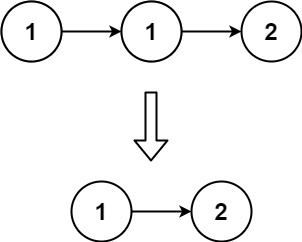
Input: head = [1,1,2] Output: [1,2]
Example 2:
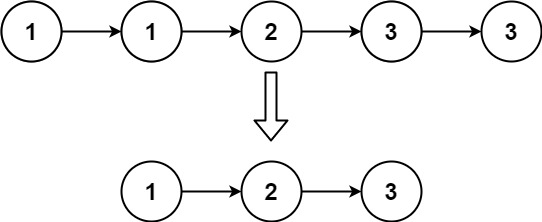
Input: head = [1,1,2,3,3] Output: [1,2,3]
Constraints:
[0, 300].-100 <= Node.val <= 100Problem Overview: You get the head of a sorted singly linked list. Because the list is sorted, duplicate values appear next to each other. Remove the extra occurrences so each value appears only once and return the updated list.
Approach 1: Iterative Two Pointers (O(n) time, O(1) space)
The sorted order gives the key insight: duplicates always appear consecutively. Traverse the linked list with a pointer called current. Compare current.val with current.next.val. If both values match, skip the duplicate node by updating current.next = current.next.next. If they differ, move the pointer forward. Every node is processed once, and duplicate nodes are removed in-place without creating new nodes.
This approach relies on pointer manipulation rather than extra memory. Because the structure is already sorted, there is no need for hash sets or additional data structures. The traversal performs constant work per node, giving O(n) time complexity and O(1) space complexity. This is the most practical solution and the one expected in interviews when working with sorted linked lists.
Approach 2: Recursive Approach (O(n) time, O(n) space)
The recursive solution processes the list from the head while letting recursion handle the rest of the nodes. Call the function on head.next to deduplicate the remainder of the list. After recursion returns, compare head.val with head.next.val. If they are equal, skip the next node by returning head.next; otherwise keep the current node and return head.
This approach mirrors the natural recursive structure of a list: each node decides whether to keep or discard its neighbor after the remainder is cleaned. The algorithm still visits every node exactly once, so the runtime remains O(n). However, recursion introduces call stack usage proportional to the list length, leading to O(n) auxiliary space. It’s a clean conceptual solution and often appears when practicing recursion with linked structures.
Recommended for interviews: The iterative two-pointer solution is the expected answer. Interviewers want to see that you recognize the sorted property and remove duplicates with direct pointer updates. Mentioning the recursive variant demonstrates deeper understanding of list processing, but the iterative approach is more memory-efficient and production-friendly.
This approach uses two pointers to traverse the linked list. It compares the current node with the next node. If they have the same value, update the next pointer of the current node to skip the duplicate. Otherwise, move to the next node. This ensures that each element appears only once while maintaining the sorted order.
This C code defines a function to delete duplicates from a sorted linked list. It uses a single while loop to traverse the list, comparing the value of the current node with the next node. If they match, the next pointer is adjusted to skip the duplicate, effectively deleting it. Memory for the deleted node is freed to avoid leaks.
Time Complexity: O(n), where n is the number of nodes in the list, since we traverse each node once.
Space Complexity: O(1), as no additional space is used apart from a few pointers.
This approach employs recursion to solve the problem. The base case checks if the current node is null or has no next node. For other cases, if the current node and the next node have the same value, the next pointer is adjusted to the result of the recursion call. Otherwise, move to the next node using recursion.
This C function utilizes recursion to remove duplicate nodes. It recursively processes nodes, checking if current and next nodes have the same value, and adjusts the pointers accordingly, freeing memory for duplicate nodes.
Time Complexity: O(n), where n is the number of nodes, each node is visited once.
Space Complexity: O(n), due to recursion stack space.
We use a pointer cur to traverse the linked list. If the element corresponding to the current cur is the same as the element corresponding to cur.next, we set the next pointer of cur to point to the next node of cur.next. Otherwise, it means that the element corresponding to cur in the linked list is not duplicated, so we can move the cur pointer to the next node.
After the traversal ends, return the head node of the linked list.
The time complexity is O(n), where n is the length of the linked list. The space complexity is O(1).
| Approach | Complexity |
|---|---|
| Iterative Approach using Two Pointers | Time Complexity: O(n), where n is the number of nodes in the list, since we traverse each node once. |
| Recursive Approach | Time Complexity: O(n), where n is the number of nodes, each node is visited once. |
| Single Pass | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Iterative Two Pointers | O(n) | O(1) | Best choice when the linked list is already sorted and you want an in-place, memory‑efficient solution |
| Recursive Approach | O(n) | O(n) | Useful for practicing recursion with linked lists or when expressing the logic recursively is clearer |
Remove Duplicates from Sorted List - Leetcode 83 - Python • NeetCode • 77,580 views views
Watch 9 more video solutions →Practice Remove Duplicates from Sorted List with our built-in code editor and test cases.
Practice on FleetCode